
大规模预训练为具身模型构建了通用的感知与执行先验,赋予了机器人基础的泛化能力。但这仅仅是机器人迈向真实世界的第一步。真实世界的部署,需要一个能够完成多种任务的通才策略机器人。并且面对复杂多变的物理环境、未曾见过的长尾任务,以及每一次执行中的偏差与失败,机器人要能够利用这些与真实世界交互的经验持续进化。
当前的具身模型训练通常只包含离线训练阶段,部署环节往往仅被视为“验证”而非“学习”的闭环。特别是真实场景中那些极具价值的经验,如环境变化引起的分布偏移、长尾任务中的探索过程,以及执行失败揭示出的能力边界等,往往未能被系统性地整合进下一轮迭代。
为了解决这一问题,上海创智学院与智元机器人具身研究中心联合发布了最新研究成果:LWD (Learning While Deploying)。这是业界第一个面向大规模真实世界部署,支持通用机器人策略从离线到在线强化学习的 VLA 训练框架。LWD 让部署中的每一台机器人既是策略执行者,也是训练数据采集节点。通过真机强化学习,LWD 将具身模型的训练方式从示教驱动真正推进到交互驱动。部署不再是模型落地后的终点,而是机器人能力持续进化的起点。
具身模型训练pipeline重构:离线到在线的的RL数据飞轮
伴随机器人集群在真实世界的规模化部署,多种多样的数据能够持续回流。LWD 这一套具身模型的离线到在线的强化学习训练范式。它的核心目标是通过一套闭环的数据飞轮,驱动 VLA 模型在真机部署中实现自我进化。
离线 RL 预训练 → 机器人集群真机部署 → 自主执行数据回流 → 在线RL后训练 → 优化后策略发送机器人集群。
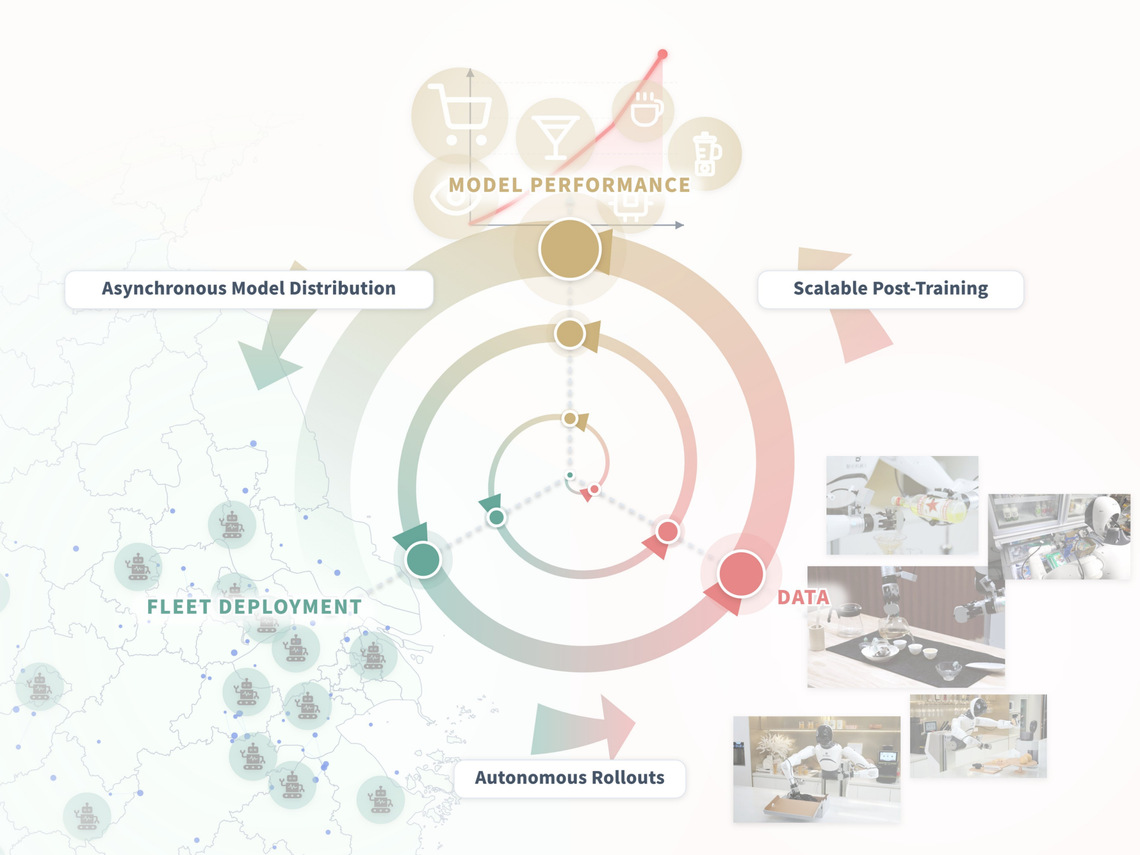
LWD 数据飞轮
系统使用 Actor–Learner 异步架构,重点打造离线到在线的统一管线。全流程共享同一套策略模型与算法目标,确保从离线示教数据到在线真机交互的无缝过渡,打造一个持续进化的通用机器人策略。
离线 RL 预训练:建立可部署的初始策略
Learner 首先在包含人类专家采集的成功轨迹、历史策略产生的成败轨迹,以及针对失败模式的人工引导性探索数据静态数据池上完成离线强化学习训练。
这一阶段为在线后训练提供一个稳定的策略 ,让价值评估器 提前建立对物理任务状态的合理估计。这能有效避免策略在接入真机、面对分布偏移时,因评判器失稳而导致的策略退化。
在线RL后训练:在真实交互中驱动飞轮
离线策略推送到机器人集群后,机器人启动自主执行。自主轨迹与人类接管数据实时汇入在线池。Learner 以约 1:1 的比例混合抽样离线与在线数据,在借离线数据锚定基础能力的同时,利用在线经验拉升性能上限。更新后的策略参数无缝同步回集群,驱动飞轮持续运转。
统一 Pipeline 的工程价值
不同于频繁切换训练目标的方案,LWD 的两阶段共享 DIVL (Distributional Implicit Value Learning) + QAM (Q-learning with Adjoint Matching) 算法。这不仅避免了范式切换带来的训练震荡,更让离线阶段的价值网络与策略能被在线阶段直接继承。真正让“从静态数据到真机部署”成为一个连贯的学习过程。
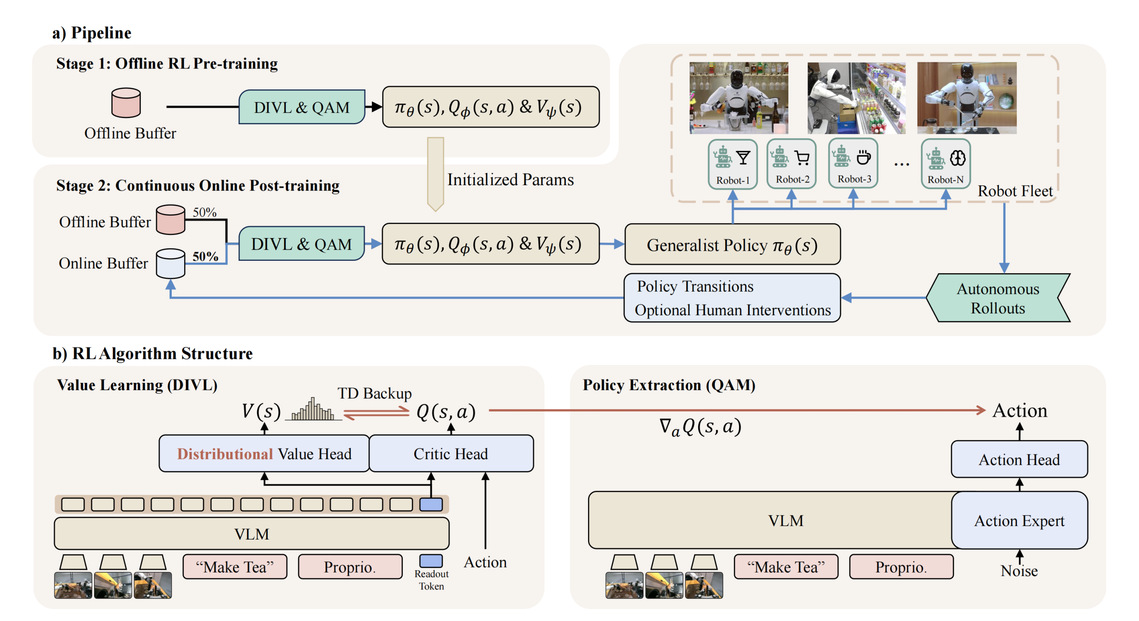
LWD 概览
算法设计:DIVL 价值估计与 QAM 策略提升
为了实现规模化的通用机器人部署,离线到在线的后训练至关重要,但也存在很多困难。长难任务稀疏的奖励信号,多样多样的机器人回放数据,离线到在线的分布转移,让值评估变得困难。而基于流模型的直接优化,也是充满了不稳定性。为此 LWD 提出了 DIVL 的值评估方法,结合 QAM 的策略优化,为大规模真实世界部署持续改进的机器人系统提供了一条实际可行的路径。
DIVL:分布式隐式价值学习
传统的 IQL (Implicit Q-Learning) 采用标量期望分位回归拟合价值,在异构集群数据回放和分布偏移下容易失稳。DIVL 将价值估计重构为分类问题:学习的分类分布,并从中提取自适应的分位作为时序差分更新目标。
其特性体现在:可扩展性(分类交叉熵在大规模数据上更易扩展)、灵活性(同分布可抽取不同统计量)、适应性(分布熵提供“价值置信度”信号)。配合多步时序差分回传,价值信号能高效地从稀疏终点反向传播至数千步之前的早期状态。
QAM:伴随匹配策略提升
针对 Diffusion 或 Flow-matching 动作头难以直接反传梯度的问题,LWD 引入 QAM 机制:将价值网络的梯度信息通过伴随状态转化为局部回归目标。这避开了挑战性的整流反向传播,且无需显式动作似然估计。DIVL 与策略更新仅通过伴随终态耦合,实现了干净、稳定的策略提取。
LWD 框架的系统级特性:
经验闭环:成败经验直接转化为训练信号,降低对人类持续示教的依赖。
无缝过渡:全流程算法统一,消除了范式切换带来的训练不稳定。
长程突破:有效解决分钟级任务、跨越数百步的信用分配难题。
性能评测:物理交互的量化收益
LWD 作为具身通用模型的闭环训练范式, 用同一模型,针对 8 个真实世界任务进行了系统评估,这其中包含4个不同类型、涉及多种物品的商超任务补货任务;以及制作功夫茶,调制鸡尾酒,制作果汁,收纳鞋子等长达3-5分钟不等,需要多种规划及精细操作的长程任务。并与 SFT、RECAP、HG-DAgger 等基线方案进行了对比。
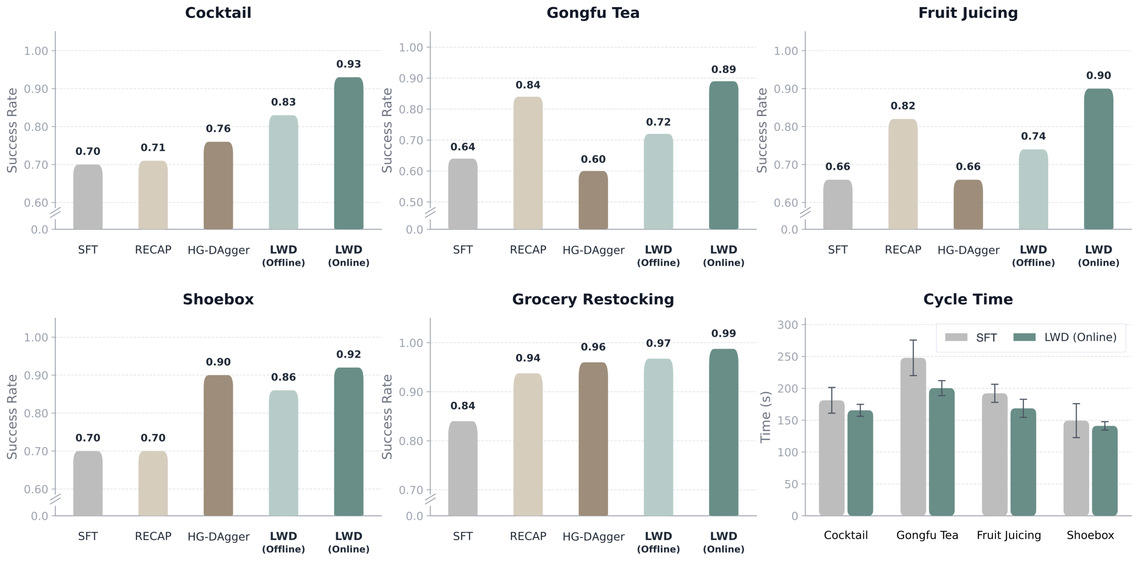
测评结果
在同一套通用策略基座下,LWD 取得了平均 95% 的成功率,显著优于所有基线方案。
在难度最高的长程任务中,性能提升尤为显著:相比离线初始化,在线 LWD 在泡功夫茶、榨果汁、调鸡尾酒、鞋盒收纳等任务上分别提升了 17%、16%、10% 和 6%。这印证了我们的判断:任务链路越长、越要求纠错与恢复能力,越能从“交互中学习”的强化学习飞轮中获益。此外,长程任务的平均周期耗时缩短了约 23.75 秒,证明模型在自主探索中收敛到了更高效的执行路径。
范式跃迁:从模仿向自主进化
回到最初的命题:如果说模仿学习让机器人初步具备了通用理解与执行能力,LWD 则推动了机器人从“复现示教轨迹”向“从自身交互中学习”的跃迁。机器人不再仅仅是示教数据的复刻者,而是在真实物理世界的磨砺中,自主寻得更优的路径与更稳健的恢复策略。
我们坚信,这条路径将从底层统一“规模化部署”与“规模化智能增长”。机器人集群越大、部署时间越长,通用策略便愈加强大。训练不再受限于过去的静态数据,智能,将在当下的每一次物理交互中持续生长。
项目研究团队简介
LWD 工作的核心贡献者为上海创智学院 2026 级博士生王一(论文第一作者)及蔡羽诺、潘铭杰、黄敬顺四位创智学子,他们深度参与并主导了从底层算法设计到真机集群部署测试的全流程研发。项目由上海创智学院全职导师、智元机器人首席科学家罗剑岚博士担任负责人并指导完成。
此次上海创智学院与智元机器人的联合攻坚,是创智践行新型“研创型大学”理念、探索独特培养模式的一个生动实例。在这里学生不再局限于传统的理论课堂,而是直接进入产业最前线,在面对极具挑战性的物理 AI 前沿命题与真实的工程挑战中,获得最宝贵的科研与实战经验。这种将产业需求与高层次创新人才培养深度融合的“创智模式”,正源源不断地为国家人工智能产业输送具备国际视野的顶尖科技人才。
