
上海创智学院OpenMOSS团队2月份发布MOSS-TTS系列开源模型,2个月来在Huggingface下载量超过60万次。本周,OpenMOSS团队再次携手模思智能正式开源了专为实时流式生成与端侧部署设计的极致轻量化模型 MOSS-TTS-Nano。发布仅3天Github Star数破千。

MOSS-TTS-Nano不仅能在纯 CPU 环境下极速运行,更打破了过去轻量级 TTS 在音质和语种上的天花板:在仅 0.1B(1亿)的极小参数规模下,原生实现了 48kHz 双声道(Stereo)的高保真输入输出,并一口气支持了全球 20 种语言。
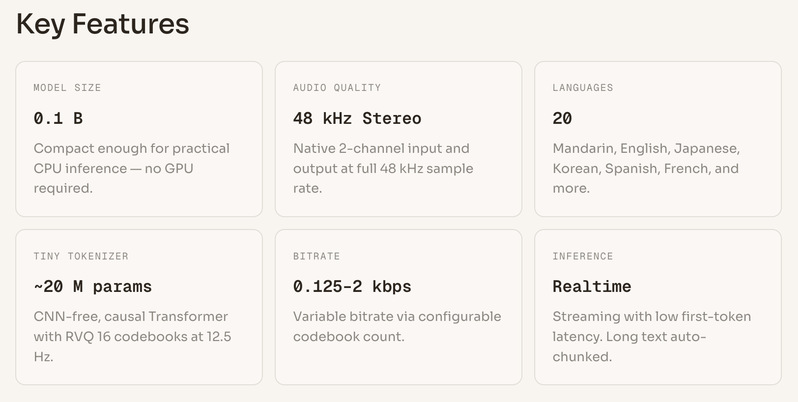
相关链接:
●GitHub 开源仓库:https://github.com/OpenMOSS/MOSS-TTS-Nano
●在线 Demo 体验:https://openmoss.github.io/MOSS-TTS-Nano-Demo/
●HuggingFace:https://huggingface.co/OpenMOSS-Team/MOSS-TTS-Nano-100M
●ModelScope:https://modelscope.cn/models/openmoss/MOSS-TTS-Nano
为什么语音交互需要一次“减负革命”?
当前主流的 Zero-shot(零样本)开源 TTS 模型在实际落地时,普遍面临着一个难以调和的矛盾:要速度,就得牺牲音质;要音质,就跑不动。
第一,令人头疼的推理延迟。为了生成几秒钟的高质量音频,大模型往往需要数秒的“思考(推理)”时间。这种延迟在对话机器人、虚拟数字人等需要“毫秒级响应”的场景中,会严重破坏用户的沉浸感。
第二,音质的天花板与空间感的缺失。过去的开源零样本 TTS 模型,大多最高仅支持 24kHz 或 16kHz 的单声道音频。这种音频听起来总有一种干瘪的“电话音”或“机器味”,完全丧失了真实环境中的空间声场与高频细节。
第三,高昂的算力门槛。动辄数十亿参数的模型,让单机部署、移动端应用或网页端实时交互面临巨大的显存与延迟压力。
第四,语种支持受限。大多数轻量级模型仅支持中英双语,难以满足日益增长的出海业务与全球化沟通需求。
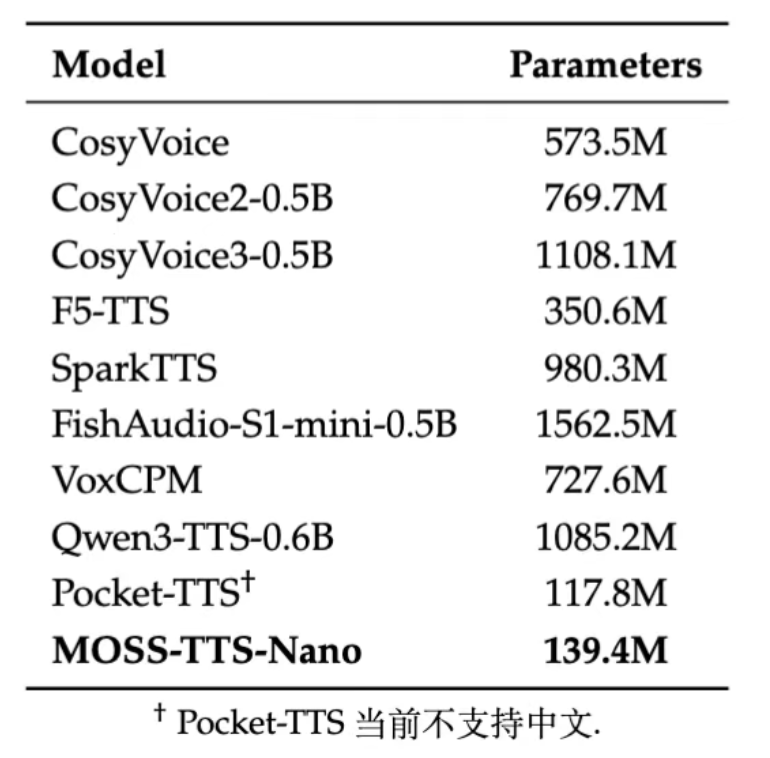
MOSS-TTS-Nano 的回答是:用极致的架构创新,在“参数做减法”的同时,实现“音质与语种的全面升舱”。下图展示了 MOSS-TTS-Nano 与主流 TTS 系统的参数规模对比:可以发现,当前大多数支持中英文的 TTS 系统参数规模集中在 1B 级别, 而 MOSS-TTS-Nano 仅用 0.1B 参数量,就实现了同等级别的核心能力。
核心技术创新:小巧,却全能
1.极致轻量化的高性能音频 Tokenizer,夯实高保真生成的底座
为了让仅仅 0.1B 的 Nano 模型拥有超越体型的录音棚级音质,OpenMOSS 团队为其量身打造并同步开源了专属的底层声学基石 —— MOSS-Audio-Tokenizer-Nano。作为 MOSS-TTS-Nano 模型的统一离散音频接口,这款 Audio Tokenizer 展现出了令人惊叹的工程美学与技术指标:
●纯 Transformer 架构,彻底告别 CNN:它基于团队自研的 Cat(Causal Audio Tokenizer with Transformer)架构构建。与过去依赖卷积神经网络(CNN)的传统 Tokenizer 不同,它完全由因果 Transformer 块组成,这使得其在处理长序列时具有更强的一致性和更低的时延。
●20M 极致微型,却打破“单声道”魔咒:在这个动辄拼参数量的时代,MOSS-Audio-Tokenizer-Nano 的参数量被极致压缩到了约 20M。但正是这极其微小的体积,却原生攻克了 48kHz 超高采样率 以及 双声道(Stereo)立体声 的高保真压缩难题。它极大程度减少了高频细节的压缩损失,让声音彻底摆脱了干瘪感,保留了真实的呼吸声、环境混响与空间方位感。
●高压缩比与变比特率:支持将 48KHz 立体声音频压缩至 12.5 fps。基于 16 层 RVQ 机制,模型可在 0.125-2kbps 范围内实现灵活的码率调节,满足不同场景下的高保真重建需求。
 MOSS-Audio-Tokenizer-Nano 架构图
MOSS-Audio-Tokenizer-Nano 架构图
MOSS-TTS-Nano 摒弃了对海量参数的盲目堆叠,采用纯自回归的 Audio Tokenizer + LLM架构,并针对延迟和音频质量进行了底层重构,实现了在极小参数量下的卓越表现。
这一设计带来了四大核心优势:
●毫秒级极低延迟: 彻底打破首字响应时间(RTF)的瓶颈。实测显示,MOSS-TTS-Nano 能够在 100 毫秒内极速出声,天然适配语音助手的实时连续对话场景。
●端侧友好,部署自由: 极致轻量的参数规模(仅 0.1B 参数),使其不仅能在单张消费级显卡上轻松运行,甚至在 CPU 或移动端边缘设备上也能实现流畅推理。
●原生零样本音色克隆(Zero-Shot Cloning): 只需要短短 3-5s 的参考音频,MOSS-TTS-Nano 就能精准捕捉说话人的音色特征和发音习惯,实现高保真的声音复刻。
●细腻的情感与韵律感知:突破了小模型“机械音”的魔咒。无论是中英混叠的自然衔接,还是抑扬顿挫的语气变化,Nano 都能处理得游刃有余。
2. 基于 Audio-Tokenizer + LLM Backbone 的端到端实时语音生成方案
有了极致强大的底层音频分词器,MOSS-TTS-Nano 是如何在仅 0.1B(100M)的极小参数下,实现毫秒级响应与录音棚音质的完美平衡的?答案在于其精巧的全局与局部协同架构(Global & Local Transformer)。从下方架构图可以看出,MOSS-TTS-Nano 采用了一种天然适配流式生成的端到端自回归范式,彻底重构了小模型的推理效率:
 MOSS-TTS-Nano 架构图
MOSS-TTS-Nano 架构图
(1)统一的多模态输入表征 (Text & Audio Tokenizer):模型打破了文本与声音的壁垒。输入的文本通过 Text Tokenizer 转化为文本 Token;同时,提示/参考音频通过 MOSS-Audio-Tokenizer-Nano 的 Streaming Audio Encoder 极速压缩为携带时序信息的音频 Token。文本与声音在输入端被统一为同一种“离散语言”,无缝融合。
(2)Global Transformer 统筹全局认知(大脑):作为模型的核心枢纽,0.1B 参数的 MOSS-TTS-Nano Global Transformer` 扮演着“大脑”的角色。它负责处理跨模态的上下文,精准捕捉文本的语义逻辑,并深刻理解参考音频中的音色特质、情感走向与停顿韵律。
(3)Local Transformer 极速发射预测(嘴巴):这是 Nano 能够实现“毫秒级流式低延迟”的核心秘诀。 为了不让主干网络被繁重的音频细节拖垮,Nano 引入了一个极其轻量的 Local Transformer。全局网络只需指明“生成方向”(输出全局潜变量),局部网络便会接管工作,极速地逐层预测出 1~16 层的 RVQ 音频 Token。这种“大统筹+小快跑”的机制,极大提升了吞吐量。
(4) Streaming Audio Decoder 实时流式解码:随着 Token 被逐帧生成,MOSS-Audio-Tokenizer 的 Streaming Audio Decoder 同步介入,将这些离散信号瞬间还原为 48kHz、双声道的高保真物理声波,实现真正的“边想边说”、“张口就来”。
正是这种极致优化的端到端架构,让 MOSS-TTS-Nano 摆脱了传统 TTS 对算力的重度依赖,真正将“实时录音棚级交互”带入了 CPU 时代。
“听”见实力:实战效果展示
百闻不如一听。为了直观展示 MOSS-TTS-Nano 的合成与复刻能力,我们在官方 Demo 网站中准备了丰富的测试用例。(强烈建议佩戴耳机,体验 48kHz 双声道带来的极致立体声场!)
(以下语音详见公众号推文链接:https://mp.weixin.qq.com/s/khnYZfthvs6E69XCA9nlRw)
场景一:零样本音色与“空间环境”高保真复刻
传统 TTS 只能模仿干声,而 Nano 连同原录音中的“环境混响”和“双声道空间感”都能一并精准克隆。只需短短几秒的参考音频,它就能完美还原目标人物的音色特征与发音习惯。
场景二:跨越 20 种语言的无缝交流
得益于统一的多模态输入表征,Nano 打破了语言壁垒。使用一个中文母语者的声音作为参考,即可让其流利地说出地道的西班牙语、挪威语、法语、荷兰语、德语、瑞典语等,口音自然,完美适配出海应用的 AI 助手交互。以下是随机挑选出的一些案例,更多演示请移步 Demo 页面 https://openmoss.github.io/MOSS-TTS-Nano-Demo。
场景三:细腻情感与长文本流式输出
内置自动分块策略,面对长篇叙述或大段情感文章,MOSS-TTS-Nano 也能在毫秒级响应后持续稳定输出,且发音抑扬顿挫、毫无“机器念稿”的生硬感。
(更多丰富演示,请移步官方 Demo 网站:https://openmoss.github.io/MOSS-TTS-Nano-Demo/ )
开箱即用:对开发者极其友好的部署体验
一个优秀的开源模型,不仅要性能强大,更要易于上手。既然 MOSS-TTS-Nano 主打极致轻量和 CPU 可用,我们也为其配备了极其友好的本地部署栈。告别复杂的环境配置和对高端 GPU 的依赖,您只需几行简单的命令,即可在本地跑起属于您的录音棚级 TTS:
1.极简环境安装:
1 git clone https://github.com/OpenMOSS/MOSS-TTS-Nano.git
2 cd MOSS-TTS-Nano
3 pip install -r requirements.txt
4 pip install -e .
2.一行命令开启本地 Web 交互界面:
1 moss-tts-nano serve
(运行后,打开浏览器访问 http://127.0.0.1:18083 即可直接在网页端体验)
3.命令行极速生成音频:
如果您是开发者,想要快速集成到自己的脚本中,只需使用自带的 CLI 命令:
1 moss-tts-nano generate \
2 --prompt-speech assets/audio/zh_1.wav \
3 --text "欢迎关注模思智能、上海创智学院与复旦大学自然语言处理实验室。"
进阶玩法:MOSS-TTS-Nano-Reader 网页朗读器
为了让大家立刻在日常生活中用上这款模型,团队不仅提供了极简的代码调用,还同步开源了一款开箱即用的浏览器扩展应用:MOSS-TTS-Nano-Reader。它将复杂的底层推理封装成了本地服务(并贴心提供了带可视化界面的桌面端控制台 App)与 Chrome/Edge 浏览器插件:
MOSS-TTS-Nano-Reader 开源仓库:https://github.com/OpenMOSS/MOSS-TTS-Nano-Reader
它将复杂的底层推理封装成了本地服务(并贴心提供了带可视化界面的桌面端控制台 App)与 Chrome/Edge 浏览器插件:
●网页一键朗读: 点击浏览器插件,自动提取网页长文并进行流式低延迟朗读。
●纯本地 CPU 运行: 零 API 调用成本,完全在本地运行,100% 保护您的阅读隐私。
●真正的“音色自由”: 支持在插件中直接添加克隆音色。你可以用喜欢的名人、甚至自己的声音,高保真地为你朗读每日新闻和干货文章。
(完整的安装与使用说明,请详见 Reader 仓库主页)
结语与开源地址
一端是极致轻量的 0.1B 参数与纯 CPU 运行的极低门槛;另一端是突破性的 48kHz 双声道高保真音质与 20 种语言的广阔覆盖。MOSS-TTS-Nano 的开源证明了:极其强大的多模态 AI 语音交互能力无需总是高高在上,它完全可以轻盈地落入每一个开发者的笔记本里、落入每一台边缘设备中。MOSS-TTS-Nano 及其底层核心 MOSS-Audio-Tokenizer-Nano 的模型权重与代码现已全面开源。我们诚挚邀请广大开发者、学术研究者以及工业界伙伴下载体验。面向未来智能时代,上海创智学院OpenMOSS 团队与模思智能希望持续打通“顶尖人才培养—前沿科研突破—产业落地转化”的创新链路,以开放协同推动基础模型与交互智能不断演进,让更先进、更可用、更普惠的人工智能真正走进真实世界,服务人的创造、沟通与生产力提升。如果您觉得这个项目对您有帮助,欢迎前往 GitHub 点亮 Star,这将会是对开源团队莫大的鼓励。
●核心链接汇总
·GitHub 开源仓库:https://github.com/OpenMOSS/MOSS-TTS-Nano
·HuggingFace 权重:https://huggingface.co/OpenMOSS-Team/MOSS-TTS-Nano-100M
·ModelScope 权重:https://modelscope.cn/models/openmoss/MOSS-TTS-Nano
·Tokenizer 权重:https://huggingface.co/OpenMOSS-Team/MOSS-Audio-Tokenizer-Nano
·官方博客:https://openmoss.github.io/MOSS-TTS-Nano-Demo/
