
 系统输入输出全貌
系统输入输出全貌
一道几何题,文字步骤写得再清楚,有些学生就是转不过来。配上图,往往一眼就懂了。这不是玄学,认知科学有明确解释:大脑处理视觉信息和语言信息走的是两条相对独立的通道。图文同时呈现,两个通道并行工作,认知负荷更低,理解更快,记得更牢。这是认知负荷理论、双重编码理论和多媒体学习原则的共同结论。问题是:配图讲题往往耗费老师大量时间,能大规模生产高质量图文讲解的工具几乎没有。现有 AI 教育工具各有缺口——纯文字答题助手没有图;视频讲题系统制作成本极高;通用图像生成模型(如 DALL·E)画不出几何精度要求的教学图。
那大模型能不能做到这件事?给它一道 K-12 题目,它能自动生成图文交织的讲解文档吗?面对这个挑战,上海创智学院2025级博士研究生毕淑真迎难而上,构建了 EduIllustrate,做出了系统性地回答。
一、研究做了什么?
EduIllustrate 包含三个部分:230 道精选题目、一套标准化生成流程、以及一个8 维度评测框架。
 四阶段生成协议概览
四阶段生成协议概览
题目来自 K12-Vista 数据集,覆盖数学、物理、化学、生物、地理五科,小学、初中、高中三个学段,共 230 题。筛选标准很明确:图能传达文字无法直接表达的空间或关系信息,有清晰的标准答案,题型足够多样。
 知识点分布图
知识点分布图
二、如何让大模型"画对图"?
直接让大模型"帮我配图解释这道题",效果往往不理想——图和题对不上,或者前后几张图风格完全不一致,读起来比没有图更累。毕淑真及其团队设计了一套四阶段生成流程,将任务拆解为可控的子步骤。
 生成协议流水线详图
生成协议流水线详图
01 第一阶段:结构化提纲
模型先把题目转化为 XML 格式的提纲,文字解释块和图示规格块交替排列。只有在图示真正有助于理解时才规划配图,不是每一步都配。
02 第二阶段:实现规划(只做第一张图)
这是整个流程的核心设计。如果每张图都独立规划,各自发明自己的视觉风格,前后一致性就无从保证。因此规划只针对第一张图:确定配色方案、标注风格、线条规范、学科专用惯例(如几何的直角标记、物理的向量箭头)。这套"视觉风格手册"随后被所有后续图继承。
03 第三阶段:代码生成与渲染
第一张图优先渲染,其完整 Manim 代码作为上下文,后续图并行生成,但都以第一张图为视觉锚点。
04 第四阶段:文档组装
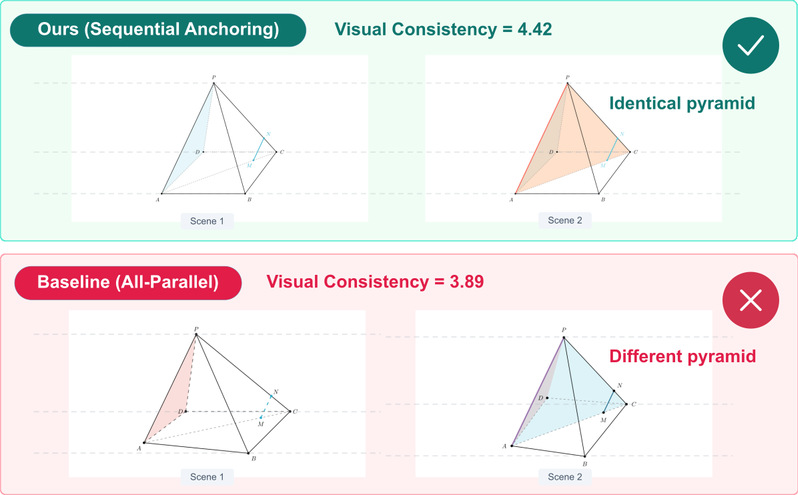
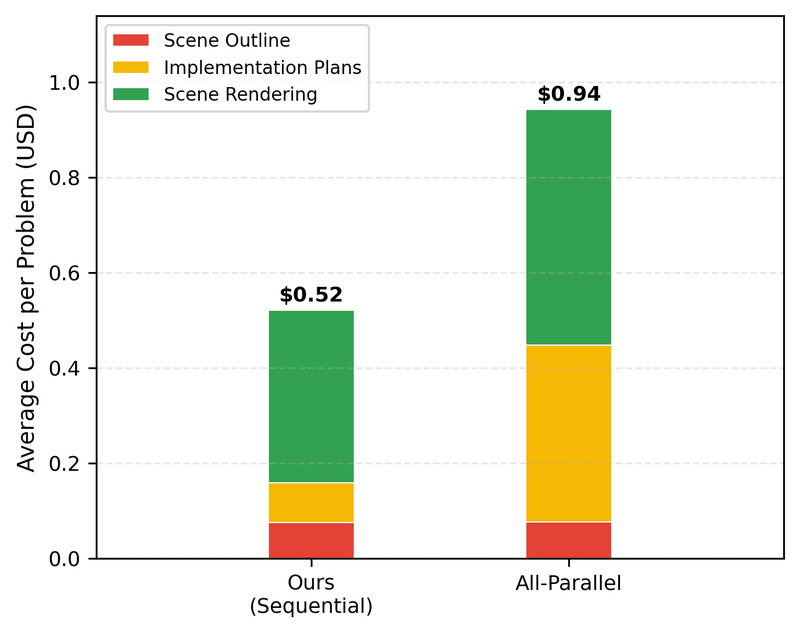
文字块与渲染图像按顺序拼合成 Markdown 文档,无需大模型参与。这种“顺序锚定“设计的效果在消融实验中得到了验证:与"每张图完全独立并行生成"相比,顺序锚定使视觉一致性提升 13 个百分点,同时输入 token 减少 51%,成本降低 47%。下面这组对比图说明了问题:同一道四棱锥题,顺序锚定的两张图是同一个锥体——第二张只是在第一张的基础上高亮了截面;而全并行基线的两张图是两个画法不同的锥体,学生需要在脑子里强行对应,认知负荷反而更高。
三、怎么评价"讲得好不好"?
研究设计了一套 8 维度评分体系,每个维度 0–5 分,换算为百分比报告。
文字质量 4 维: 正确性与完整性(推理过程和结论是否正确)、逻辑连贯性(推理步骤是否自然衔接)、教学有效性(语言是否符合对应学段、是否有效引导理解)、排版清晰度(数学符号和格式规范)。
视觉质量 4 维: 图题对齐(图是否忠实呈现题目的几何或物理设置)、元素布局质量(有无重叠、间距是否合理)、视觉一致性(多张图之间风格是否统一)、图文协调性(文字引用与图示内容的契合度)。
评测使用 Gemini 3.0 Pro Preview 作为自动裁判(温度=0)。为验证 AI 裁判的可靠性,研究另外邀请了 20 位评分员(15 名理工科研究生和 5 名教育学博士生)对 30 道题进行人工评分,产生4200 条独立判断。
四、测了 10 个模型,发现了什么?
10 个主流大模型(包括 Gemini、GPT-5、Claude、Kimi、Qwen 系列、Mistral 系列)在完整 230 题上跑完,结果如下:
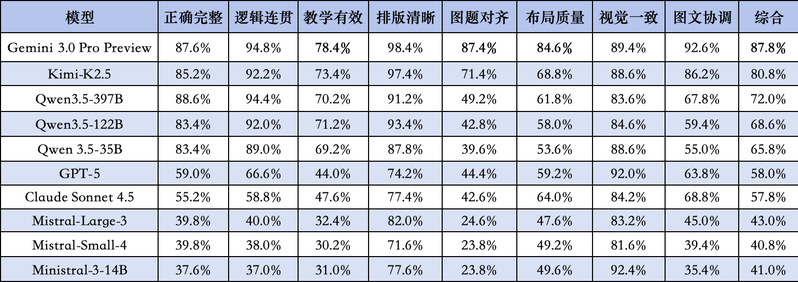
综合分取 8 维度几何平均值,任何一个维度极低都会拉低总分。
 10模型8维度雷达图
10模型8维度雷达图
几个值得关注的发现
●图题对齐是最大的视觉挑战
Mistral 系列图题对齐仅 23.8%,Qwen3.5-35B 也只有 39.6%。让图真正"画对题意"而非仅仅"看起来像那么回事",是当前大模型的核心视觉瓶颈。
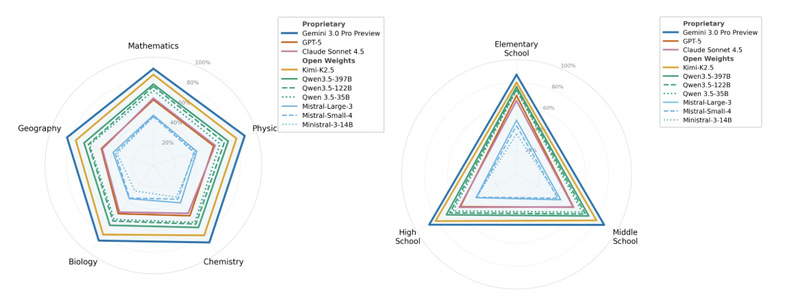
●题越难,图越难画准
小学题得分普遍高于初中,初中高于高中。数学最高,地理最低。
●教学有效性是所有模型的共同短板
得分范围仅 30%—78%,即便最强的 Gemini 也只有 78.4%。大模型可以"答对题",但用符合对应学段认知水平的语言、用有效的教学策略"讲清楚题"——这件事对所有模型都难。
四、AI 裁判靠谱吗?
 人工评估打分系统
人工评估打分系统
人工评测的数据给出了明确答案:可信度因维度而异。
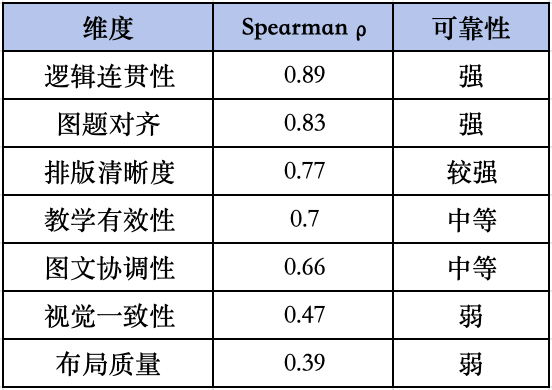
逻辑连贯性(ρ=0.89)和图题对齐(ρ=0.83)与人类评委高度吻合,AI 裁判可信。布局质量和视觉一致性则是明显短板——元素重叠、标签错位这类低层次视觉瑕疵,人类一眼能发现,视觉语言模型往往忽略。研究还比较了用 Gemini 打分和用 GPT-5 打分的差异:两个模型都存在自我评分偏高的倾向,但 Gemini 的自我偏好(+9.2%)远小于 GPT-5(+20.6%),且不影响整体排名,因此选 Gemini 作为主裁判。
五、贵的一定好吗?
 成本-质量散点图
成本-质量散点图
Kimi-K2.5 是性价比最优的选择:每题 $0.12,综合得分 80.8%,以 Gemini 四分之一的成本实现了九成的质量。相比之下,Claude Sonnet 4.5 每题 $0.41,综合得分却只有 57.8%——比 Kimi 贵 3 倍多,得分低 23 个百分点。最便宜的 Ministral-3-14B 只需 $0.01/题,但成功生成率仅 17.4%,实际可用性极低。
各阶段成本分解显示,场景渲染是所有模型中占比最大的成本来源。
 各阶段成本分解图
各阶段成本分解图
六、还差在哪里?
研究本身也明确指出了当前的局限:流水线输出的是静态图片,无法覆盖动画的时序和节奏;评测框架对布局质量和视觉一致性的定义仍需完善(人类评委之间的一致性也偏低,说明这两个概念本身还没有被精确定义);现有系统对所有学生输出同样的图文讲解,无法根据个体基础做调整。后续方向包括:引入多轮对话和苏格拉底式追问,以及根据学生画像生成个性化的图文解释策略。AI 教育的下一个问题,不是"答对题",而是"讲清楚题"。 这个问题比想象中更难,也因此更值得认真对待。
●项目主页:https://ecnu-innospark.github.io/EduIllustrate/
●数据集:https://huggingface.co/datasets/keqianli/EduIllustrate
●论文链接:https://arxiv.org/abs/2604.05005
