
在多模态大模型竞争日趋白热化的当下,视频理解正在成为衡量模型"真正智能"的关键试金石。
与静态图像不同,视频要求模型同时理解空间细节、时间逻辑和物理运动——这不仅是技术难题,更是通往具身智能和通用人工智能的必经之路。然而,当前主流视觉理解模型仍大多基于"将视频帧拼接后送入Transformer"的简单范式,面对长视频时序推理、实时动态响应等场景时捉襟见肘。
由上海创智学院全时导师邱锡鹏教授领衔的OpenMOSS团队,自 2023 年发布国内首个开源对话大模型MOSS以来,持续深耕多模态智能的前沿探索。作为学院重点打造的标杆项目,MOSS-VL从数据体系构建、模型架构创新到大规模训练工程,实现了全链路自主攻关。MOSS-VL 系列承载着团队对下一代视觉智能的核心思考——不仅要让 AI "看得清",更要让 AI "看得懂、跟得上、想得深"。
近日,OpenMOSS团队正式开源MOSS-VL视觉理解模型。MOSS-VL是一个11B参数的多模态视觉理解大模型,采用全新的交叉注意力架构,在大幅降低推理延迟的同时,在视频理解方面显著超越领先的开源模型Qwen3-VL,在多模态感知、推理和文档理解等方面均保持行业顶尖水准。
🔗开源链接:
Github:https://github.com/OpenMOSS/MOSS-VL
Demo:https://openmoss.github.io/MOSS-VL-Demo
HuggingFace:https://huggingface.co/OpenMOSS-Team/MOSS-VL-Instruct-0408
ModelScope:https://www.modelscope.cn/models/openmoss/MOSS-VL-Instruct-0408
一、为什么视频理解需要一次"架构革命"?
当前主流的视觉大模型(如 Qwen3-VL等)在视频理解时,通常将视频帧与文本一起拼接成超长序列,由同一个 Transformer 进行处理。这种方案面临三个根本性挑战:
第一,计算效率的天花板。视频的帧数动辄成百上千,将视觉 Token 和文本 Token 拼接后,自注意力的二次复杂度使推理延迟快速膨胀。这意味着模型越强,用得越慢。
第二,时间建模的缺失。 传统方案中,帧与帧之间的时间关系仅靠 Token 排列顺序隐式表达,模型难以精确感知"这件事发生在第几秒"。
第三,走向实时的瓶颈。未来的AI助手不应只是"看一张图、答一段话"的工具,而应能持续理解视频流,并自主判断何时该开口。这要求极低的推理响应——而现有架构远未达到这一水平。
MOSS-VL 的回答是:用交叉注意力从根本上解耦视觉编码与认知推理。
二、核心技术创新
1. 交叉注意力架构:解耦视觉与语言
不同于将视觉 Token 和文本 Token 拼接后统一处理的主流范式,MOSS-VL采用基于交叉注意力(Cross-Attention)的架构设计。在该架构中,视觉编码器独立处理图像/视频输入,语言模型通过交叉注意力机制按需检索视觉信息——而非被迫处理全部视觉 Token。
这一设计带来了三个核心优势:
●低延迟推理:语言模型的自注意力计算不再被海量视觉 Token 拖累,推理速度大幅提升。
●原生交错模态支持:可以在统一流水线中处理复杂的图像-视频混合序列,无需额外的预处理。
●为实时交互铺路:低延迟特性使模型天然适配视频流的实时理解场景。
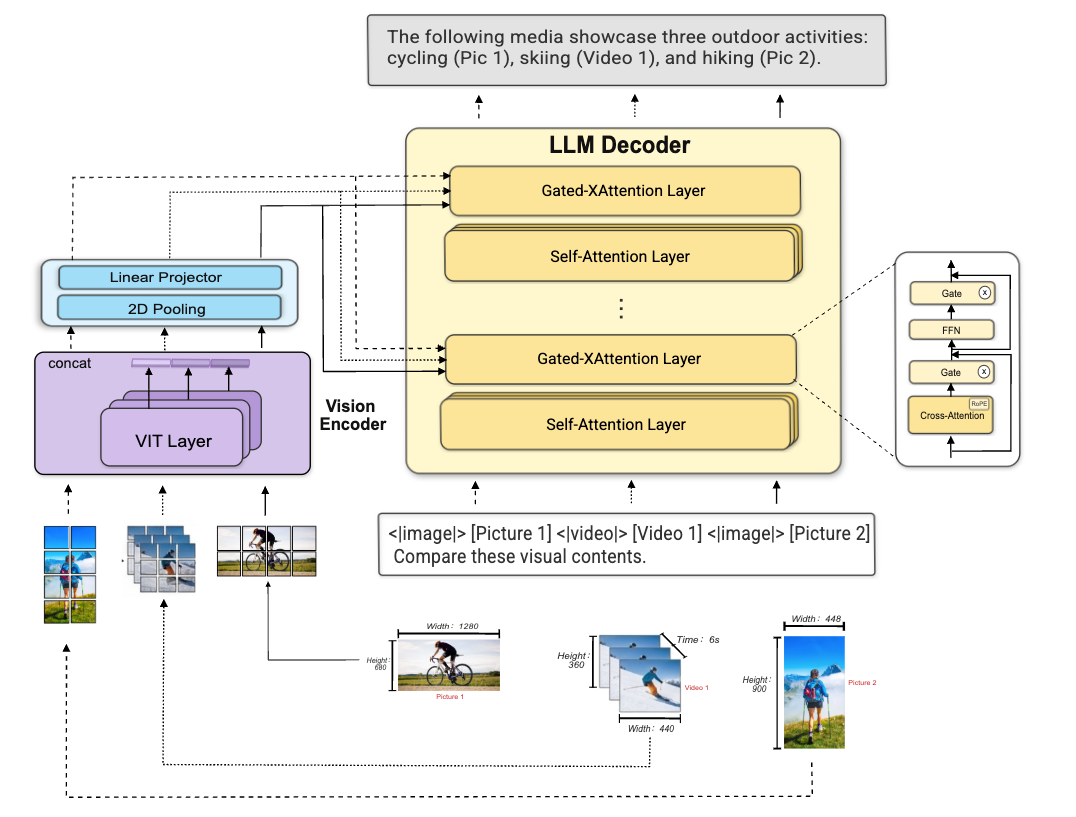
MOSS-VL 模型架构图
2. 绝对时间戳:确保模型能够精准感知事件的节奏与时长
MOSS-VL 在每一采样帧中均注入了绝对时间戳(Absolute Timestamps),从而将推理过程锚定在精确的时间参考基准之上。
●可变帧率适配: 使用显式时间戳处理非均匀采样率。无论采样率如何变化,模型都能保持精准的时间感知。
●精准动作定位:引入绝对时间维度,实现细粒度的动作定位,使每一项响应都能精准锚定在特定的时间坐标上。
●运动动力学推理:通过时间间隔(dt),模型对运动物理规律进行推理,实现对速度、加速度和运动轨迹的精确估算。
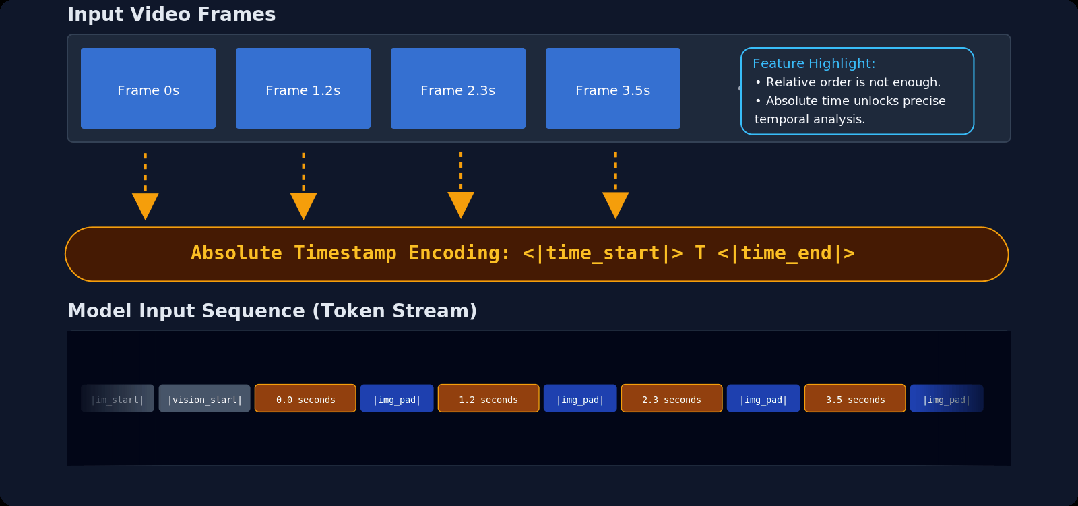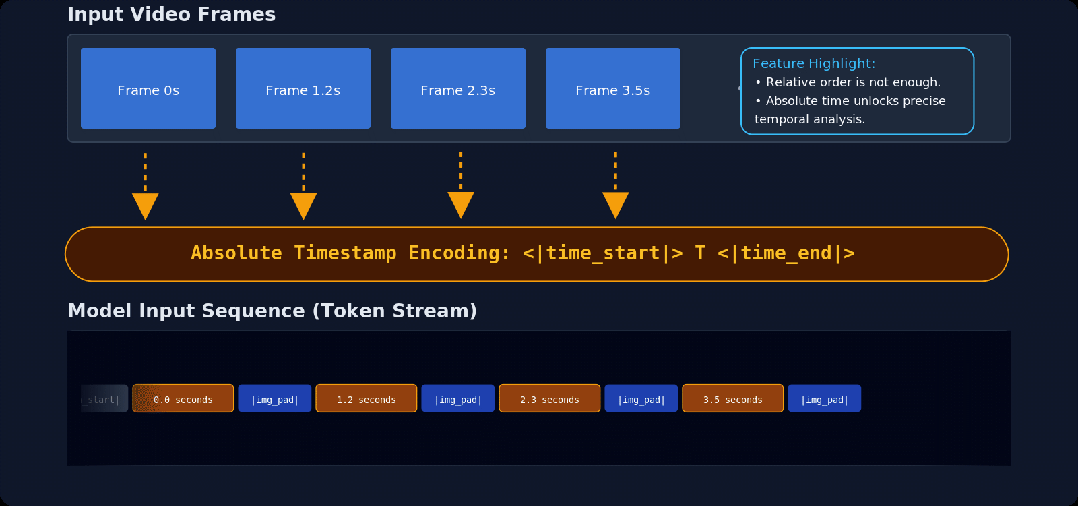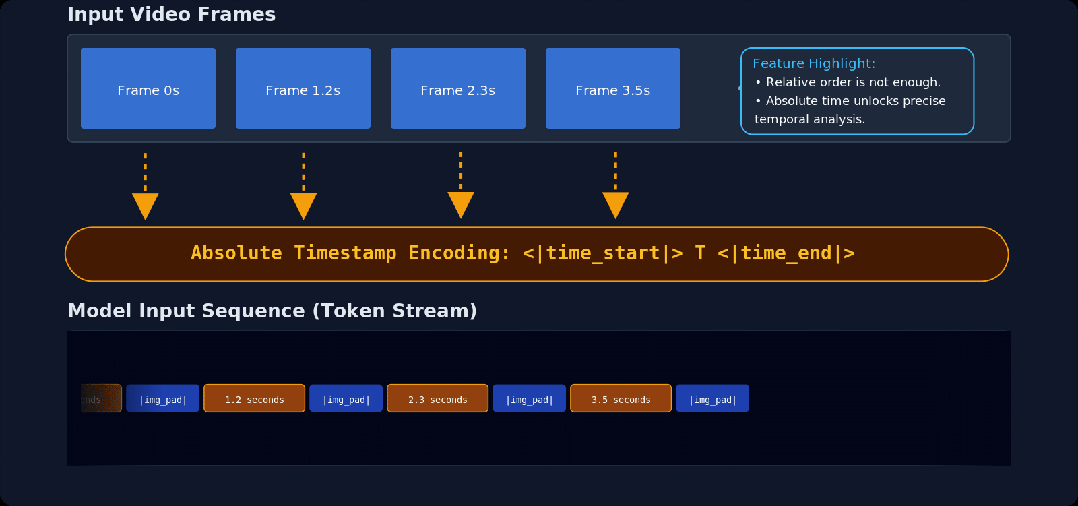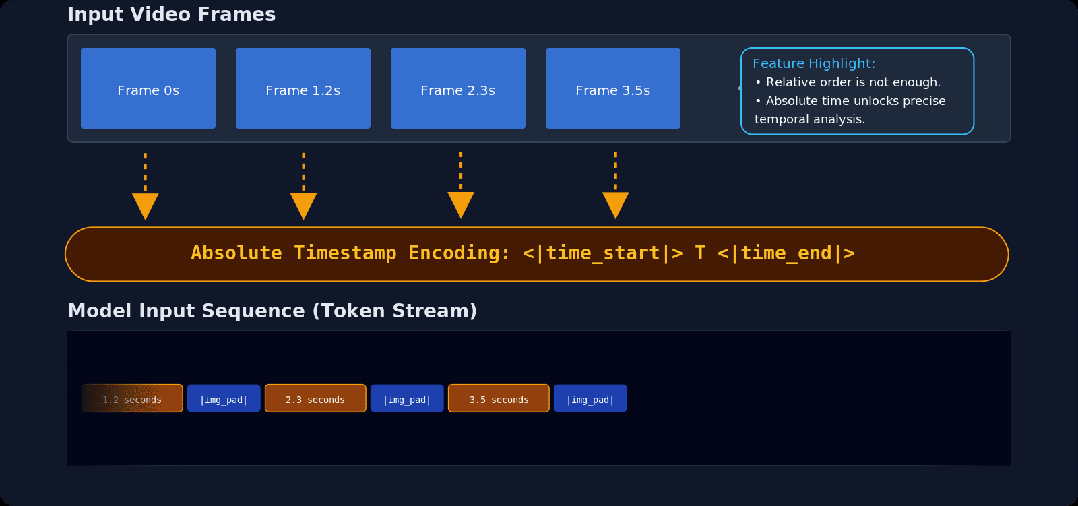
带有时间戳的视频序列输入示意图
3. XRoPE:跨模态统一的 3D 位置编码
MOSS-VL 提出了交叉注意力旋转位置编码(Cross-attention RoPE, XRoPE),将文本 Token 和视频 Patch 映射到一个统一的 3D 坐标空间——由时间 (t)、高度 (h) 和宽度 (w) 三个维度定义。
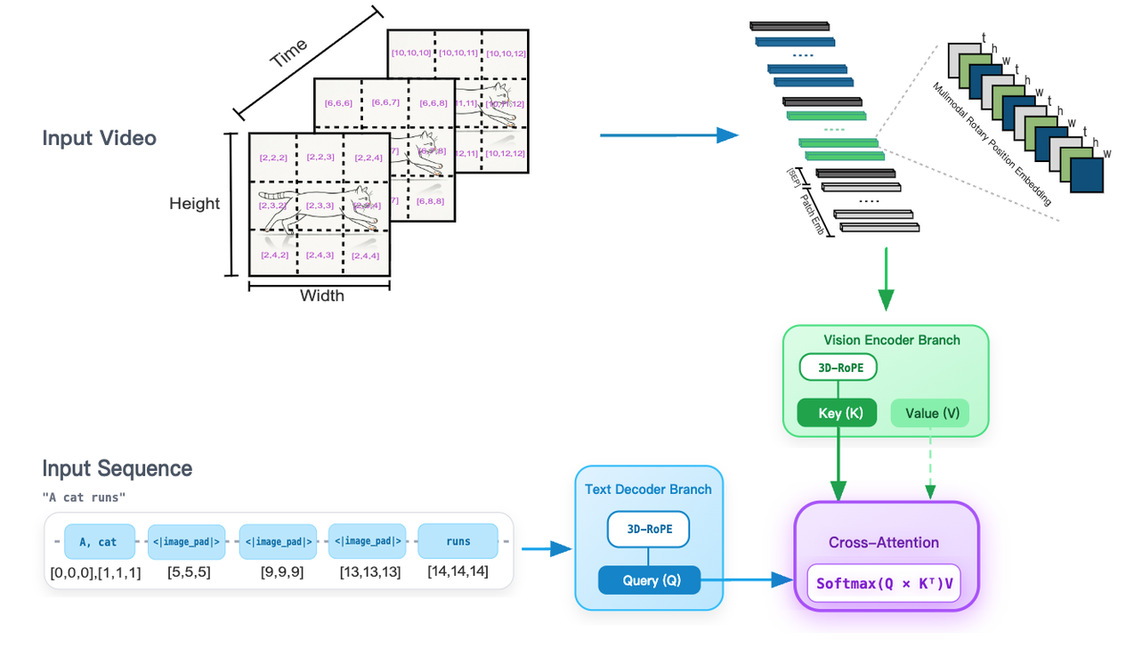
XRoPE 示意图
XRoPE 被注入到视觉端的 Key 中以增强位置感知,同时应用于文本端的 Query,使模型能够通过坐标对齐精准地检索任意时空区域的信息。
●统一的时空建模:视频和文本在同一个坐标系中进行推理。
●精准时空锚定:可定位到具体的 Patch 和瞬间。
●动态输入支持:原生适配任意分辨率和宽高比。
三、评测结果
研究团队对 MOSS-VL 在四个关键维度上进行了全面评估:多模态感知、多模态推理、文档/OCR、以及视频理解。评估结果表明,MOSS-VL 取得了卓越的性能,尤其在通用多模态感知和复杂视频分析方面表现出色。
1. 关键亮点
🚀 领先的视频智能:MOSS-VL 在视频理解维度显著超越 Qwen3-VL。在 VideoMME、MLVU、EgoSchema 以及 VSI-bench(领先 Qwen3-VL-8B-Instruct 达 8.3 个百分点)等基准测试中,它展现了出色的时序一致性和动作识别能力。
👁️ 卓越的多模态感知:MOSS-VL 展现了出色的通用图文理解能力,在 BLINK 和 MMBench 等评测中,其细粒度物体识别和空间推理表现突出。
🧠 稳健的视觉推理:MOSS-VL 展现了扎实的逻辑推断能力,在 VisuLogic 等复杂推理任务中,与 Qwen 系列的最新版本保持高度竞争力。
📄 可靠的文档理解:虽然模型主要针对通用感知和视频能力进行了优化,但 MOSS-VL 在 OCR 和文档分析方面依然确保了在文本提取和结构化信息处理中的可靠性。
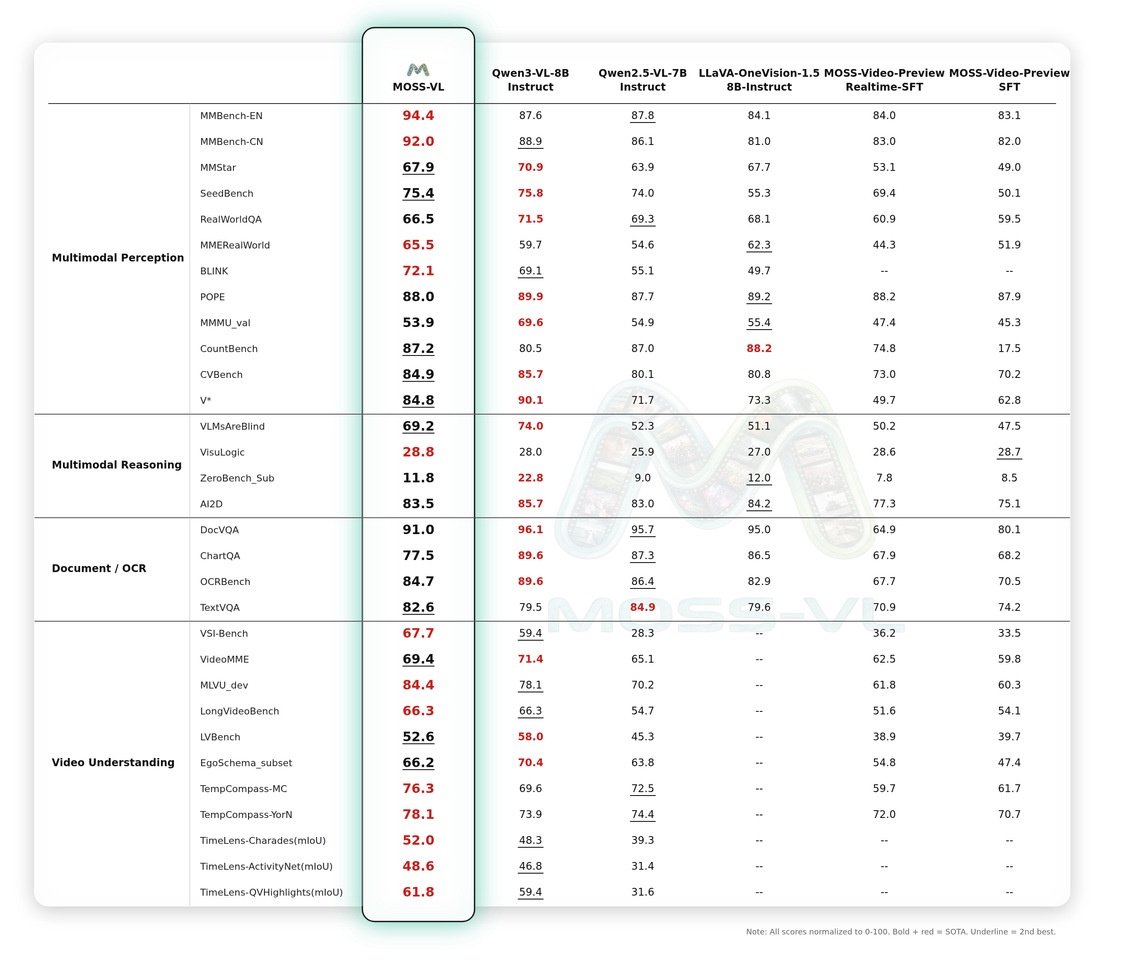
Benchmark 评测结果
2. 评测分析 (Benchmark Analysis)
下图直观展示了 MOSS-VL 在 30 多个专业基准测试中平衡且全面的能力画像。如绿色实心区域所示,MOSS-VL 实现了最广泛的综合覆盖,尤其在视频理解与多模态感知象限中展现出了卓越的性能优势。
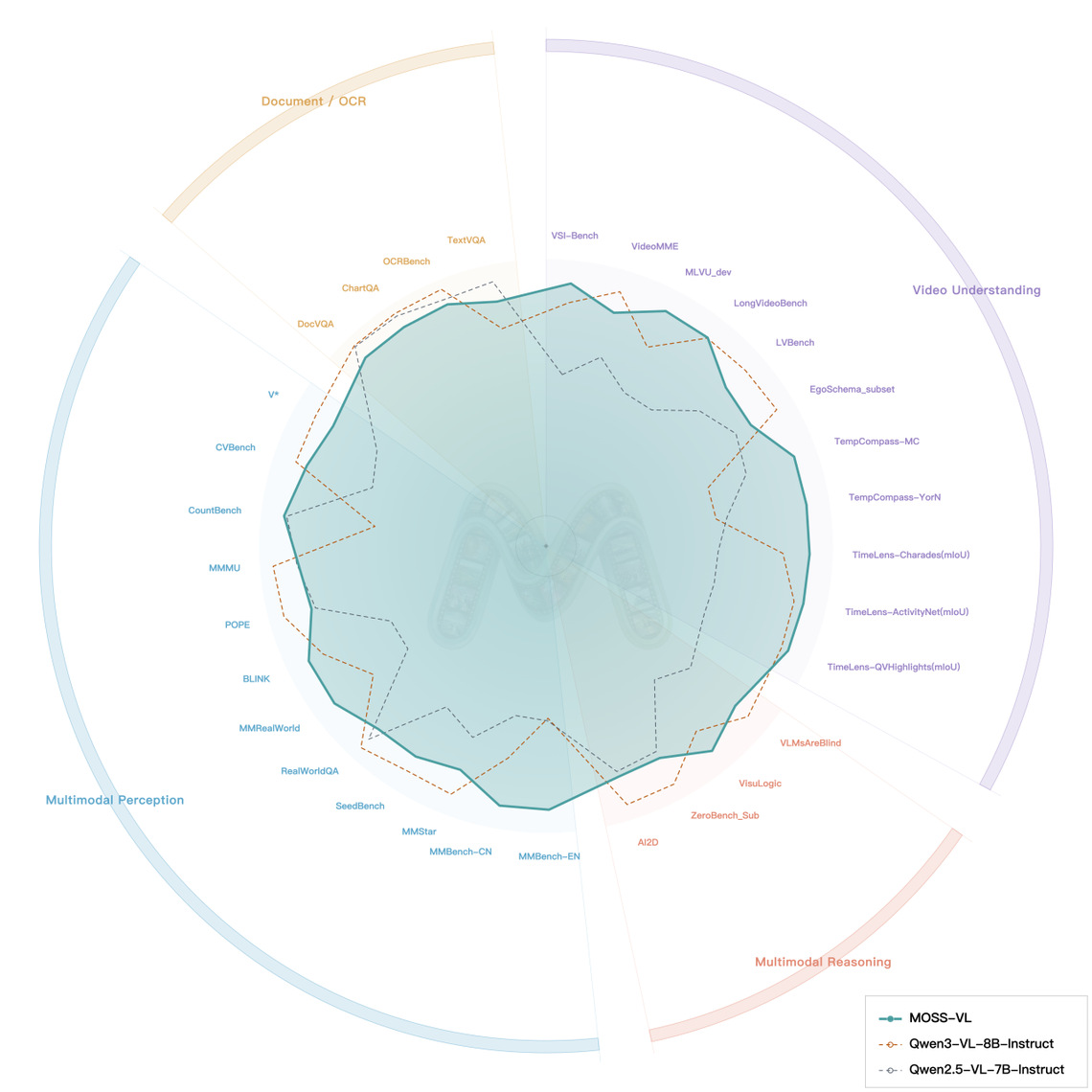
MOSS-VL 评测分析雷达图
四、视频理解实战案例
为了直观展示 MOSS-VL 的视频理解能力,以下选取了几个具有代表性的视频测试场景。
1. 星球大战
面对经典的《星球大战》开场滚动字幕,MOSS-VL 展现出卓越的视频 OCR 能力,能够在画面持续滚动的过程中逐行精准识别并完整还原大段英文文本,充分体现了模型在动态场景下的文字捕捉与长文本输出能力。
2. 罗老师买咖啡
在罗永浩的星巴克"中杯、大杯、特大杯"名场面中,MOSS-VL 能够精确追踪多轮对话中人物的表情变化、情绪波动和核心矛盾。
→问题:描述一下这段视频发生了什么?
Qwen3-VL:根据柜员的说法,柜台上三个杯子分别对应小杯、中杯、大杯。
MOSS-VL:中杯、大杯和特大杯。
3. 大开门
在这段猫咪喂食的短视频中,MOSS-VL 能够精准识别每一次喂食动作的发生时刻,完整捕捉猫咪进食的细节与次数,展现出更强的时序感知与细粒度事件计数能力。
→问题:视频中猫咪一共被喂食了几次,具体时间是?
Qwen3-VL视频中猫咪一共被喂食了3次,具体时间如下:1. 第一次喂食发生在 0:11,猫咪被喂食后表现出高兴的样子。2. 第二次喂食发生在 0:22,猫咪再次被喂食,继续表现出高兴的样子。3. 第三次喂食发生在 0:37,猫咪第三次被喂食,依然表现出高兴的样子。这三次喂食都伴随着猫咪的积极反应,如抬头、张嘴、舔舐等动作,显示出它对食物的喜爱和满足感。
MOSS-VL猫咪一共被喂食了五次。第一次在00:03,第二次在00:12,第三次在00:18,第四次在00:27,第五次在00:37。
五、从 MOSS-VL 到 MOSS-VL-RealTime:技术路线图
MOSS-VL 系列的终极愿景是 "极其强大的视觉感知推理底座 + 全天候流式实时交互范式"。当前开源的 MOSS-VL 是这一技术路线中的关键一步——夯实基础感知与认知能力。
在此基础上,将逐步推进视觉多模态底座模型的研发:
●MOSS-VL-1.5:数据体系重构与 Scale Up + 基于强化学习(RL)的推理能力强化
●MOSS-VL-2.0:探索 MoE、线性注意力等架构创新,解决超长视频连续无损理解的终极难题
●MOSS-VL 的每一步,既是在扎实地夯实视觉多模态底座,更是向着赋予 AI "实时、敏锐且具备深层逻辑的智慧之眼"的目标迈进。
六、模型下载与使用
MOSS-VL 采用 Apache 2.0 开源许可,欢迎学术研究和商业应用。
MOSS-VL-Base-0408
●HuggingFace: https://huggingface.co/OpenMOSS-Team/MOSS-VL-Base-0408
●ModelScope:
https://www.modelscope.cn/models/openmoss/MOSS-VL-Base-0408
MOSS-VL-Instruct-0408
●HuggingFace:https://huggingface.co/fnlp-vision/MOSS-VL-Instruct-0408
●ModelScope:https://www.modelscope.cn/models/openmoss/MOSS-VL-Instruct-0408
