
训练大语言模型,数据质量是一道大关。面对数百种数据类别,研究人员通常只能手工设计清洗规则——既慢又难验证。最近,来自上海创智学院、库帕思与上海交通大学GAIR团队的研究人员提出了一种不同思路:让AI自己进化出数据清洗策略。这些策略最终被用于清洗千亿级token的预训练语料,产出了高质量的预训练数据集。
问题从哪里来
现代预训练语料库来自大规模网络爬取,原始数据天然充斥各种噪声:HTML标签混入正文、广告语夹在论文段落中、LaTeX公式渲染错误、引用残缺、重复段落……更麻烦的是,不同类别数据的"脏法"完全不同——
●医学文本:临床术语不统一、药名缩写混乱
●数学文本:公式符号损坏、定理引用不完整
●计算机文本:代码块混入注释残骸、HTML标签污染正文
面对这种多样性,过去只有一条路:请专家,逐类分析,手动设计清洗规则。这条路有两个根本性的瓶颈。
其一是设计成本。现代预训练语料库往往覆盖数百个类别,每个类别都需要领域专家深入分析,耗时耗力,难以规模化。
其二是验证成本。判断一套规则是否有效,严格意义上需要跑完完整的数据清洗和模型训练流程——动辄数千GPU小时。这个代价,让"反复调整、持续优化"几乎不可行。
于是问题卡在这里:规则难设计,效果难验证,规模化更难。
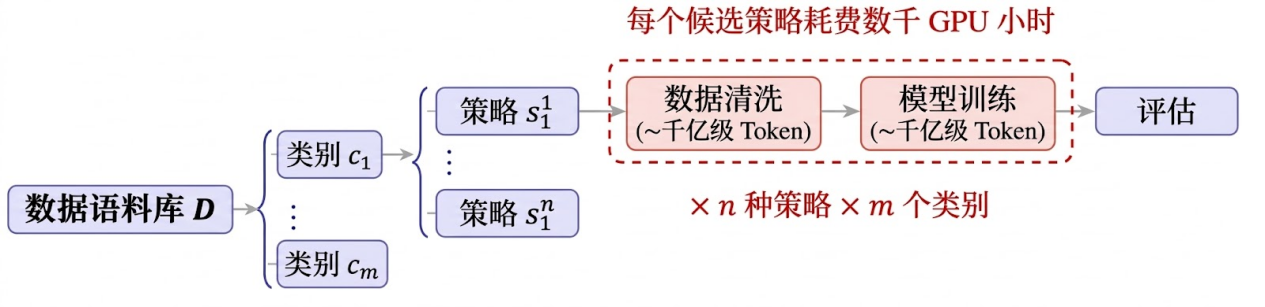
每种策略都需要完整的数据清洗与模型训练才能评估效果,导致计算成本随“策略×类别”数量快速增长
核心思路:把策略设计变成自动进化
DataEvolve的出发点很简单:既然人工设计规则走不通,那就让策略自己迭代出来。框架的核心是一个针对每个数据类别独立运行的闭环优化系统,包含四个模块:
●数据观察器:从样本中识别质量问题,记入经验库
●策略设计师:结合经验库与上一代策略的诊断反馈,生成新一代清洗策略
️●数据清洗器:在小批量样本上执行清洗,产出原文与清洗后的文档对
●质量评判员:对文档对打分,发现新问题,更新经验库
每一代策略在上一代的基础上改进,策略库中得分最高的方案最终用于全量清洗。这套循环有一个关键的工程设计:用样本级质量评分替代完整模型训练来近似策略效果。 这一步把验证成本从"数千GPU小时"压缩到"对几十个样本打分",让快速迭代真正成为可能。
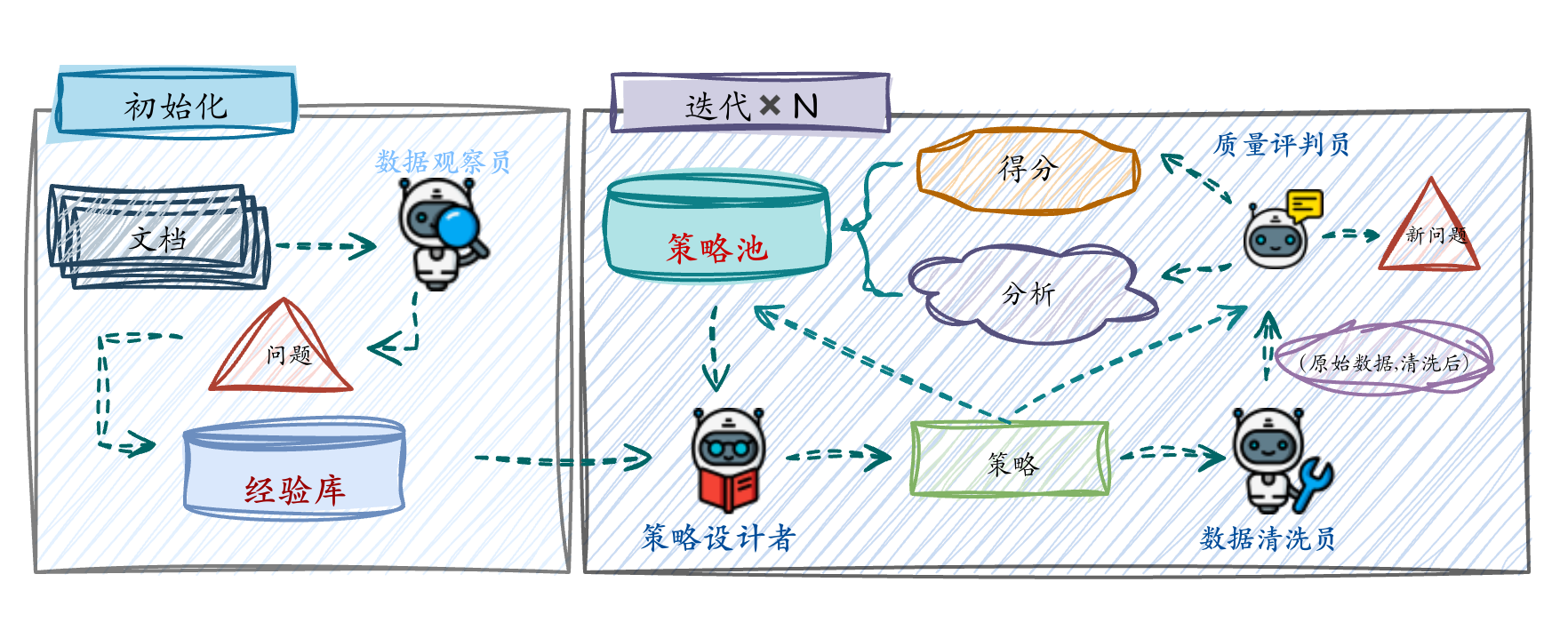
DataEvolve框架示意图:多个AI角色协作完成数据观察、策略生成、数据清洗与质量评估,并通过经验池与策略池不断迭代优化清洗策略。
实验结果
DataEvolve在现有的预训练数据集Nemotron-CC数据上进行实验。研究者首先使用文档分类模型对语料进行分类,并从中选取了8个类别作为实验对象。在这些类别上,系统分别进化清洗策略,对原始672B token数据进行处理,最终得到Darwin-CC(504B token),约25%的低质量内容被移除。
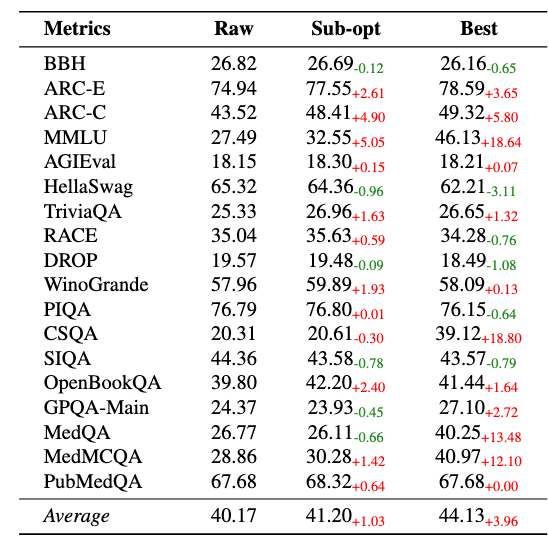
研究者使用3B参数模型在500B token上训练,并在18个基准测试上进行评估。与未经处理的原始数据相比,Darwin-CC将平均成绩从40.17提升到44.13,提升3.96分。知识密集型任务上提升尤为明显,例如MMLU(综合学科知识测试)提升18.64分,MedQA(医学问答测试)提升13.48分。
1.一个关键的消融实验
论文还做了一组非常关键的对比:同样是自动化清洗,唯一的区别是策略来自哪里。
进化优化后的最优策略 →44.13分
策略池中次优策略 →41.20分
两者相差2.93分,差距完全来自策略本身的质量。这说明:自动化清洗并不等于有效清洗。只有经过持续迭代优化的策略,才能真正释放数据价值。换句话说,DataEvolve的关键不只是“用AI清洗数据”,而是让清洗策略在迭代中不断进化。迭代进化,不是装饰,是核心。
不同数据清洗策略在benchmark上的性能对比 |
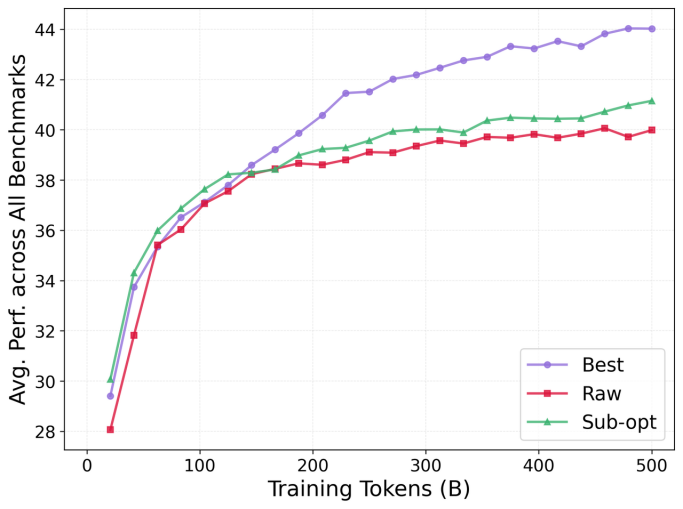
随着训练token增加,不同数据清洗策略下模型的平均性能变化 |
2.与现有数据集的对比
论文还将Darwin-CC与多个主流预训练数据集进行了横向比较,包括:FineWeb-Edu、Ultra-FineWeb、DCLM。在相同训练设置下,Darwin-CC取得44.13的最高平均分,超过第二名DCLM(42.42)。
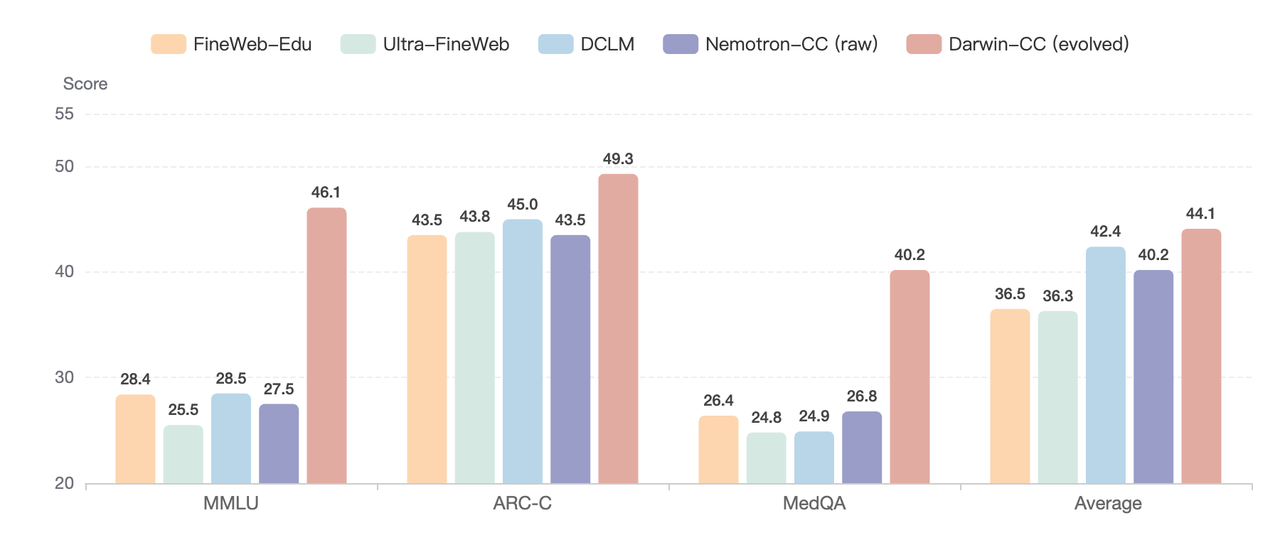
不同预训练数据集的性能对比
3.一个有趣的收敛现象
8个类别各自独立进化,互不干涉,最终策略却呈现出高度一致的形态——都在做同一件事:删掉噪声,保住原文,不做特别的改写。
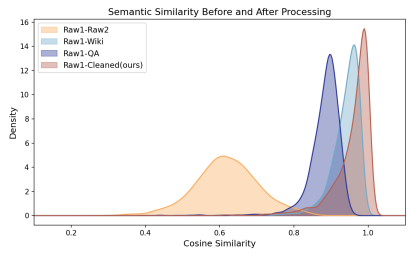
具体来说,是三类操作的组合:删除网络垃圾(HTML标签、导航菜单、广告文案、重复句子);规范格式(空白字符、标点、数字表达);加上领域感知的保护规则——数学保留定理和证明,医学保留临床单位和药名,计算机科学保护代码块和技术语法。研究者随机抽取1500篇文档,比较清洗前后的语义相似度,DataEvolve清洗后的文本几乎保持原始语义,只是去除了噪声。
这与当前流行的另一类方向形成了对比——将网页文本改写为教科书风格、问答对话或Wikipedia条目。这类"转化型"方法会生成新内容,但也会抹去原始文本的语言多样性,并引入统一风格。
DataEvolve进化出来的策略没有走这条路。系统自己得出的结论是:原始内容本身有价值,把表面的噪声清理干净就已经可以大幅提升价值。这恰恰对应了此前该团队所提出的达尔文进化框架的L4级别的处理。
文本清洗示例:去除噪声内容,同时保留原始语义。 |
不同数据处理方法下文本语义相似度分布对比(越接近1说明语义越接近原文) |

4.局限不能略过
清洗并非对所有任务都有正向效果。在HellaSwag、SIQA、PIQA等依赖口语化、非正式语言的任务上,清洗后模型表现反而略有下降。研究者的分析是:清洗在去除噪声的同时,也移除了口语化和非正式表达,使语言分布整体偏向正式文本,导致模型在这类任务上的适应性下降。
这是一个值得关注的取舍:清洗提升了知识密度,但也付出了代价。 如何在两者之间找到平衡,仍是开放的问题。


写在最后
DataEvolve解决的问题很具体:在不依赖人工设计、不依赖全量训练验证的前提下,为每个数据类别自动找到有效的清洗策略。但它更大的意义,在于提供了一条可规模化的路径。当预训练语料库覆盖数百个类别时,逐类人工介入注定难以为继,而让策略在数据上自动进化,才是更具可持续性的方向。
如果说过去的数据清洗是"人告诉机器怎么做",DataEvolve迈出的是另一步:让AI自己摸索出该怎么做。这个方向,或许才刚刚开始。
论文与资源
●论文全文
https://github.com/GAIR-NLP/DataEvolve/blob/main/report.pdf
●项目代码
https://github.com/GAIR-NLP/DataEvolve
●数据集
https://huggingface.co/datasets/GAIR/Darwin-CC
