
"市面上一个高质量的训练环境,能卖到几千块。" |
我们做了45,320个,全部开源。
贵,因为它真的重要。重要到什么程度?如果说大模型时代比拼的是"会不会答",那智能体时代比拼的,已经变成了"会不会做"。把大模型比作"会做题的学生",智能体更像是"真正进公司上班的人"。会做题,不代表会干活。会写代码,不代表能在真实仓库里找到问题、修改代码、跑通测试、根据报错继续迭代,最后把任务真正交付。过去很长一段时间,行业谈智能体,焦点大多落在模型、推理、后训练和强化学习上——大家都在想办法把"脑子"练得更聪明。但当智能体真正走向软件工程、科研、办公等复杂场景,一个事实越来越清晰:智能体 的上限,往往不是先被模型卡住,而是先被环境卡住。
这也是为什么斯坦福 教授Percy Liang给出了一个鲜明判断:"I think it's pretty clear that simulation is the next frontier for AI."
下一阶段AI真正的竞争,不只是模型能力的竞争,更是环境、是simulation——是让智能体在真实世界式反馈里不断试错、持续成长的竞争。
来自上海创智学院&上海交通大学GAIR团队正式发布daVinci-Env——一个面向软件工程智能体训练、完全透明开源的环境合成框架。
它不只是放出一批数据,而是把环境本身、生成流程、评测脚本、基础设施一并公开:
45,320个可执行Docker环境,覆盖12,800+个真实代码仓库
环境构建成本$89.1万,加上轨迹采样与难度筛选$57.6万,总投入约$147万(折合人民币千万级)
最终沉淀约13,000条高质量训练轨迹,来自约9,000个质量保证环境
这套环境不是"摆设",而是经过下游训练结果真正验证的:基于这批轨迹训练出的OpenSWE-32B和OpenSWE-72B,在SWE-Bench Verified上分别达到62.4%和66.0%,刷新Qwen2.5系列同规模最好成绩。
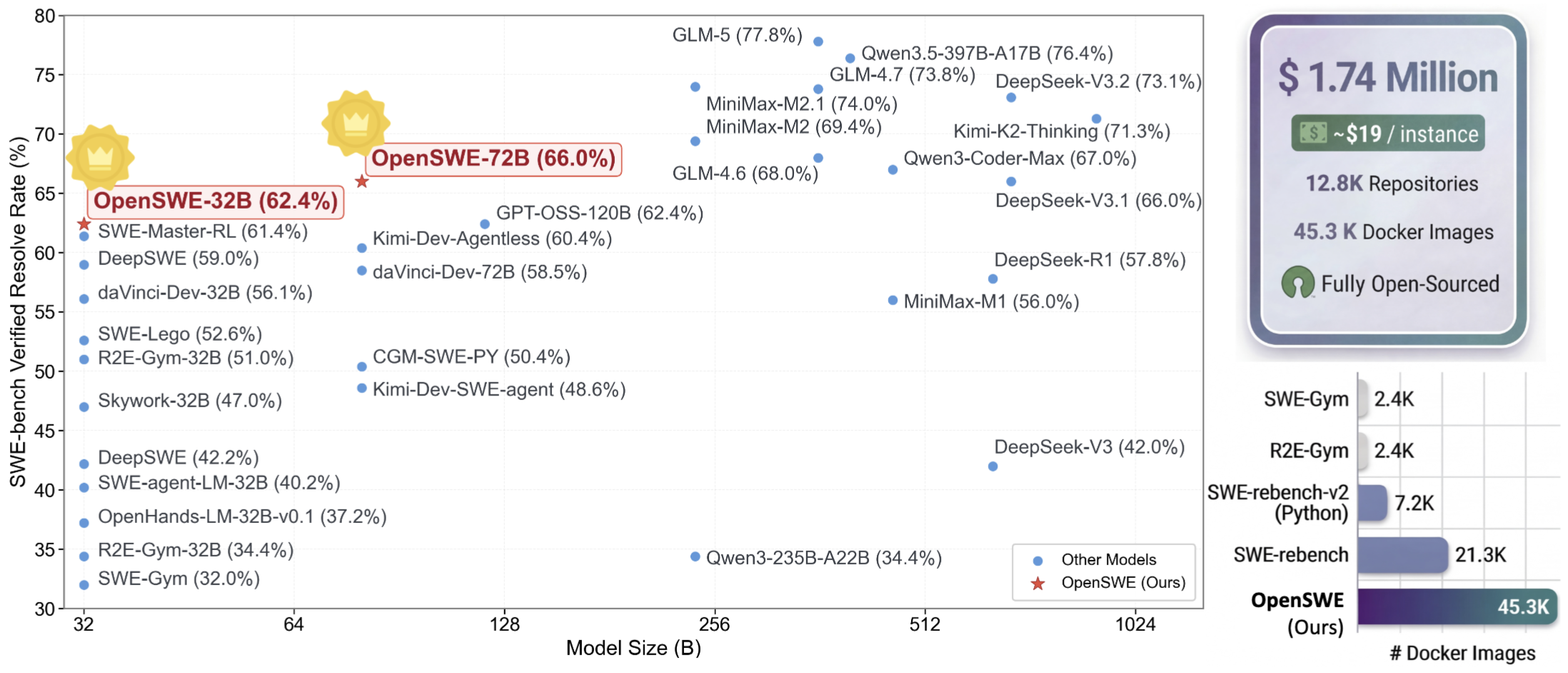
OpenSWE性能与软件工程环境镜像构建概览
为什么说智能体时代最稀缺的不是模型,而是环境?
在静态代码生成时代,模型看见一段上下文,补全一段代码,很多任务就结束了。但软件工程智能体面对的不是“补全”,而是一个完整工作流:理解需求、定位文件、改代码、处理依赖、跑测试、观察失败、修正方案,再验证结果。这类系统需要的不是静态样本,而是可执行、可验证、能提供动态反馈回路的环境。智能体必须在这些环境里编译、执行、测试,并根据运行结果不断修正自己的行为。问题是,过去开源世界里最稀缺的,恰恰就是这种环境。一方面,已有开源工作在规模和仓库覆盖上依旧有限;另一方面,工业界虽然能做到更大规模,却往往并不公开底层基础设施。
更关键的是,环境不是越多越好。如果一个环境对应的解决方案和实际问题根本对不上,智能体 再怎么努力也不可能解出来;如果题目描述几乎把答案直接说出来,那这种环境又太简单,几乎没有训练价值。OpenSWE想解决的是在开源世界里第一次把 「大规模环境合成」 这件事,做成一套可复现、可验证、可扩展的基础设施。

团队发现的两种低质量数据情况:左侧是实际问题和解决方案无法对齐;右侧是问题太过于简单。
方法亮点:让环境构建从“手工活”变成“多智能体流水线”
OpenSWE的核心方法,是一条部署在大规模集群上的多智能体环境合成流水线。整套框架主要包含以下几个阶段:GitHub PR收集与过滤、仓库探索、Dockerfile构建、评测脚本生成、环境验证、测试分析,以及多机并行构建。这一整体流程在论文第4页的框架图中有清晰展示。
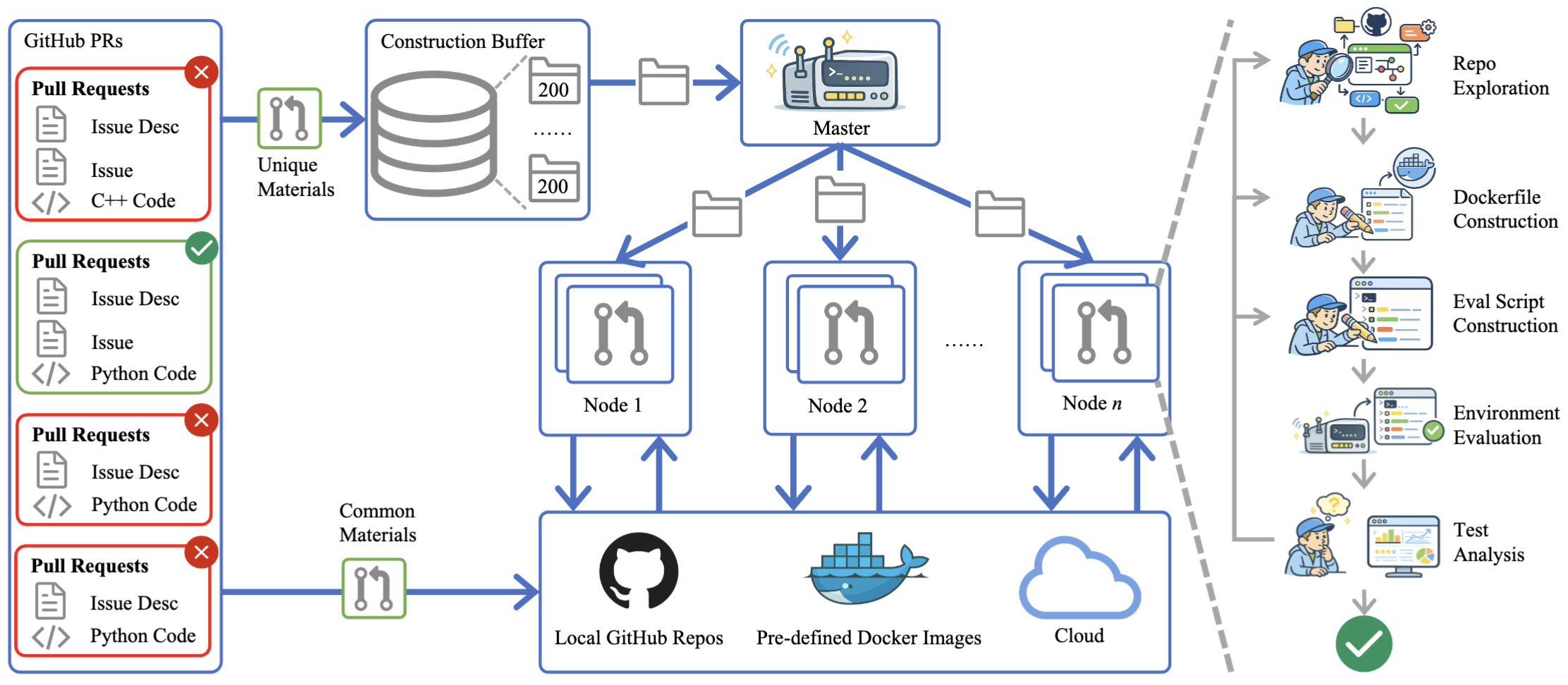
OpenSWE框架架构
研究团队首先通过GitHub REST与GraphQL API,从大量Python仓库中抓取PR元信息、关联issue描述、提交序列和patch。随后,构建了一个四阶段过滤流程,只保留满足以下条件的PR:
仓库至少有一定社区活跃度;
主语言为Python;
必须有关联issue且issue描述非空;
修改必须涉及非测试代码,而不只是测试目录。
这一步的目的很明确:先保证任务来源真实、问题描述存在,再尽可能排除“伪任务”与低价值样本。
在真正构建环境之前,OpenSWE先让一个轻量级的仓库探索智能体进入本地仓库,只围绕环境搭建和测试运行相关信息做有限探索。它通过浏览(browse)、搜索(search)、消化(digest)等受限接口,重点查找README、依赖清单、CI配置、测试说明等高价值文件,以更低成本为后续Docker构建和评测脚本生成提供上下文。这相当于在正式动工前,先让 智能体 把“这个仓库该怎么装、怎么测”摸清楚。
3)Dockerfile智能体:专门解决大规模构建中的“网络不稳”和“重复重建”
论文指出,环境构建在实践中最常见的两个失败模式是:
使用通用基础镜像时,需要在构建阶段临时下载Python和依赖,容易因网络波动频繁超时;
Docker层设计不合理,导致每次迭代都要重复重建大量不变内容,成本极高。
为此,OpenSWE提出了几项非常工程化、但也非常关键的优化:
预构建覆盖Python 2.7与3.5–3.14的基础镜像;
维护本地bare repo cache,避免在容器里现拉代码;
提示智能体将稳定基础层前置、依赖安装后置,以便最大化Docker缓存复用;
强化对conda激活、开发模式安装、测试延迟执行等Python细节的约束。
这些设计的本质,是把“智能体会写Dockerfile”推进到“智能体能在大规模真实环境里稳定产出可复现Dockerfile”。
4)评测脚本智能体:让“是否修好”变成可自动判定
仅有Docker环境还不够,还必须有一套可靠的评测脚本来判断patch是否真正解决了问题。OpenSWE的评测脚本智能体会自动生成bash脚本,负责:
选择与issue相关的测试;
必要时补充新的测试用例;
记录测试输出边界与退出状态;
将最终是否修复成功编码为明确标记,供后续系统解析。
相比传统固定fail-to-pass脚本,这种方法更灵活,也更适合自动构建的新环境。
5)测试分析智能体:不只看“过没过”,还看“是不是作弊过的”
在环境验证完成后,OpenSWE还会引入一个测试分析智能体,对通过或失败的结果进行进一步检查。若测试通过,它会确认评测脚本没有通过硬编码退出代码(exit code)等方式“投机取巧”;若测试失败,它则分析究竟是Docker配置错误、测试脚本错误,还是这个环境本身就不可解,并把有针对性的反馈返回给上游智能体继续修正。这一步很重要,因为它把环境合成从“自动生成”推进到了“自动质检”。
为了把这套流程跑到大规模,团队部署了一个由64台ECS实例组成的分布式集群,对约572,114个GitHub PR并行处理。整套系统专门考虑了大规模构建中的几个现实难题:外部API与网络的不稳定、Docker资源争抢、进程中途崩溃、磁盘被僵尸容器占满等。对应地,OpenSWE采用了几项非常务实的基础设施设计:
数据并行、节点尽量解耦,避免单点故障拖垮全局;
通过共享文件系统上的消息队列管理任务分发;
用systemd托管合成进程,实现自动恢复;
部署自动清理守护进程,持续清除僵尸容器和无用镜像;
使用Prometheus + Grafana进行全流程监控。
最终,在标准化配置下,这个64节点集群于约两周内完成了45,320个验证通过的环境构建。单节点配置包括32个虚拟CPU核、128GB内存、20Gbps内网带宽和4TB SSD。

分布式集群的硬件和软件配置
OpenSWE有多大?它已经超过现有最大的开源软件工程训练环境
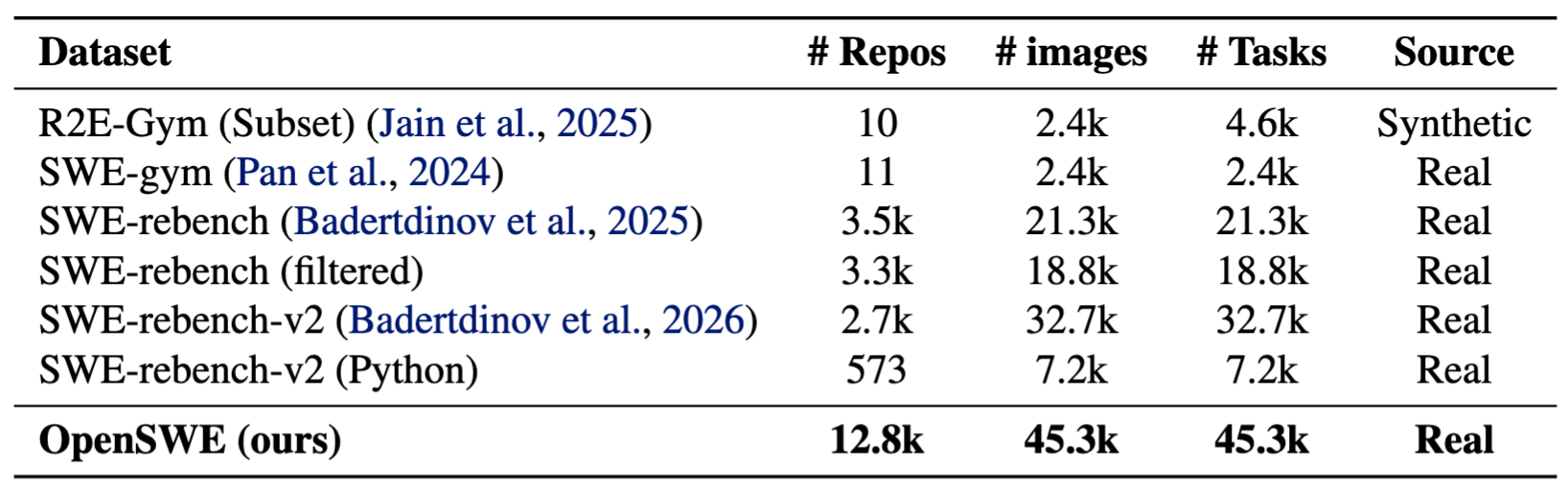
在与现有软件工程训练数据集的对比中,OpenSWE在可执行仓库数量和任务规模上都达到了当前公开方案中的最高水平之一:
12.8k repositories
45.3k images / tasks
作为对比,论文中列出的SWE-rebench-v2(Python)为573个仓库、7.2k任务;SWE-rebench(filtered)为3.3k仓库、18.8k任务。OpenSWE在真实仓库覆盖面和任务规模上都显著更大。
在核心实验中,研究团队基于OpenSWE训练了32B和72B两个规模的模型,并分别在OpenHands与SWE-Agent两种智能体脚手架下评测SWE-Bench Verified。结果显示:
OpenSWE-32B + SWE-Agent:62.4%
OpenSWE-72B + SWE-Agent:66.0%
OpenSWE-32B + OpenHands:59.8%
OpenSWE-72B + OpenHands:65.0%
其中,32B与72B两个规模都达到当时文中所称的SFT方法新最优。论文特别强调,即便使用的是非Coder基座模型,OpenSWE依然能取得非常有竞争力的结果,这说明高质量训练环境本身,就能够显著增强软件工程智能体的能力上限。
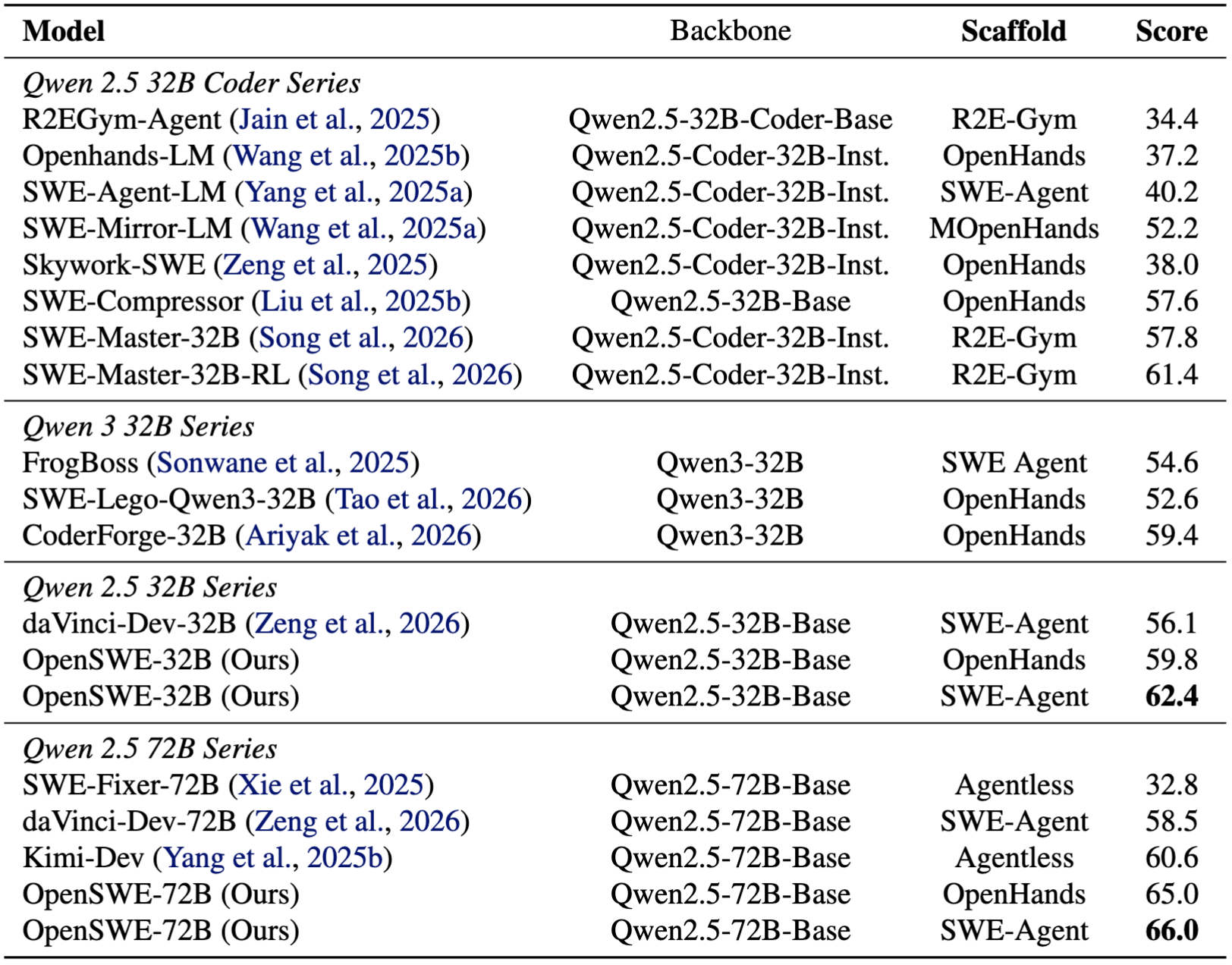
OpenSWE与其他代表性方案在SWE-Bench Verified测试集上的比较
📊核心发现一:高质量环境,比“堆更多旧数据”更有效
论文专门比较了不同环境来源对训练效果的影响。结论非常直接:只用OpenSWE训练,整体上显著优于只用SWE-Rebench。以32B + SWE-Agent为例:
SWE-Rebench:50.2%
OpenSWE:62.4%
绝对提升达到12.2个点。在其他设置下,OpenSWE也都稳定领先。这意味着,对软件工程智能体来说,训练数据不是“越像就越好”,而是需要更强的环境真实性、任务有效性与仓库多样性。
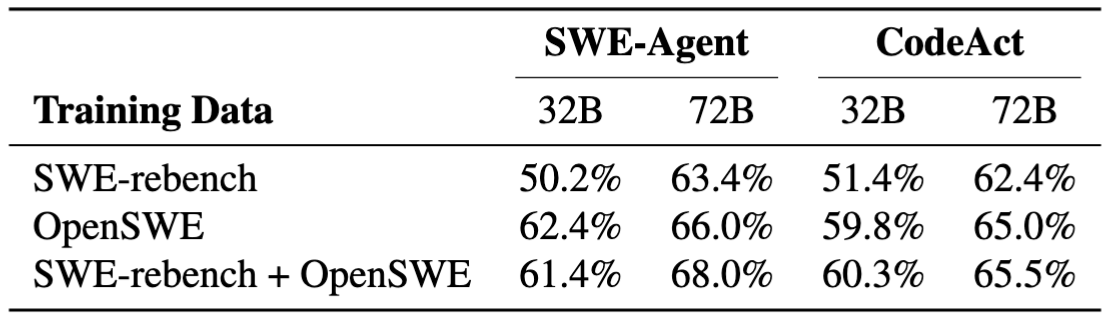
合成环境来源在不同模型大小和智能体脚手架上对训练效果的影响
📈核心发现二:数据规模还没到头,性能仍在持续上涨
为了研究数据规模与性能之间的关系,团队进一步对不同训练步数下的模型表现进行了分析。结果表明,在32B / 72B、SWE-Agent / OpenHands四种组合下,OpenSWE的性能曲线都表现出近似log-linear的持续增长趋势,且没有观察到明显饱和。这意味着一个非常重要的判断:软件工程环境合成这条路,远没有走到尽头。如果能继续扩大高质量环境规模,软件工程智能体的训练效果很可能还会继续提升。
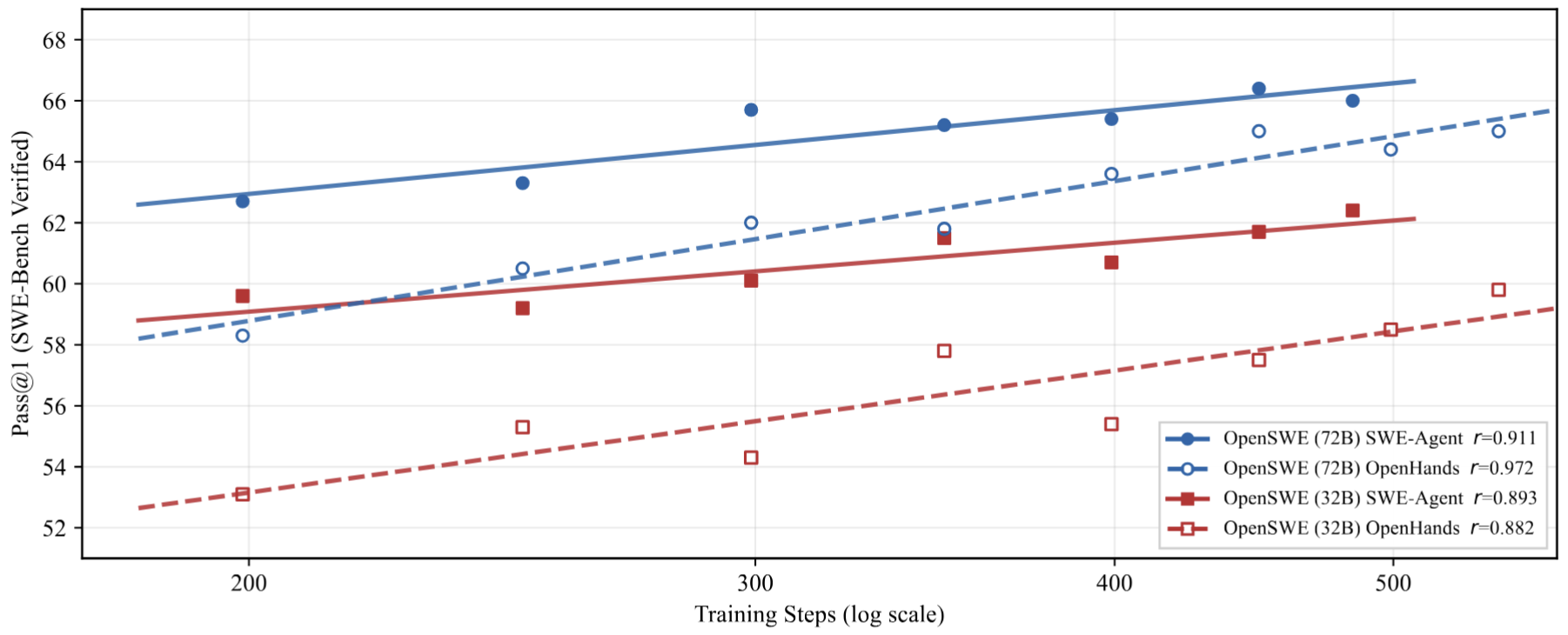
OpenSWE的数据规模增长曲线:在不同模型尺寸和不同智能体框架下,性能如何随着数据量提升而变化,一目了然。
🧠核心发现三:软件工程训练不仅提升“修Bug”能力,还提升代码、数学与科学推理能力
一个常见担心是:如果模型只在软件工程数据上训练,会不会变得“只会修代码”,反而牺牲通用能力?OpenSWE的结果给出了相反答案。论文显示,相比基础模型,OpenSWE训练后的模型在多个通用能力基准上均有提升:
32B模型在HumanEval上提升+29.09
32B模型在HumanEval+上提升+31.23
数学推理任务GSM8K / MATH-500也有稳定增益
SuperGPQA和SciBench等科学类评测同样提升
而MMLU基本持平、TriviaQA仅小幅上升,说明事实性记忆没有被破坏。
论文对这一现象的解释也很有启发性:软件工程训练本质上锻炼的是多步规划、逻辑拆解、阅读—编辑—验证闭环,这些能力天然可以迁移到代码生成、数学推理和部分科学推理任务中;但对于依赖预训练知识覆盖的纯事实记忆任务,影响则相对有限。
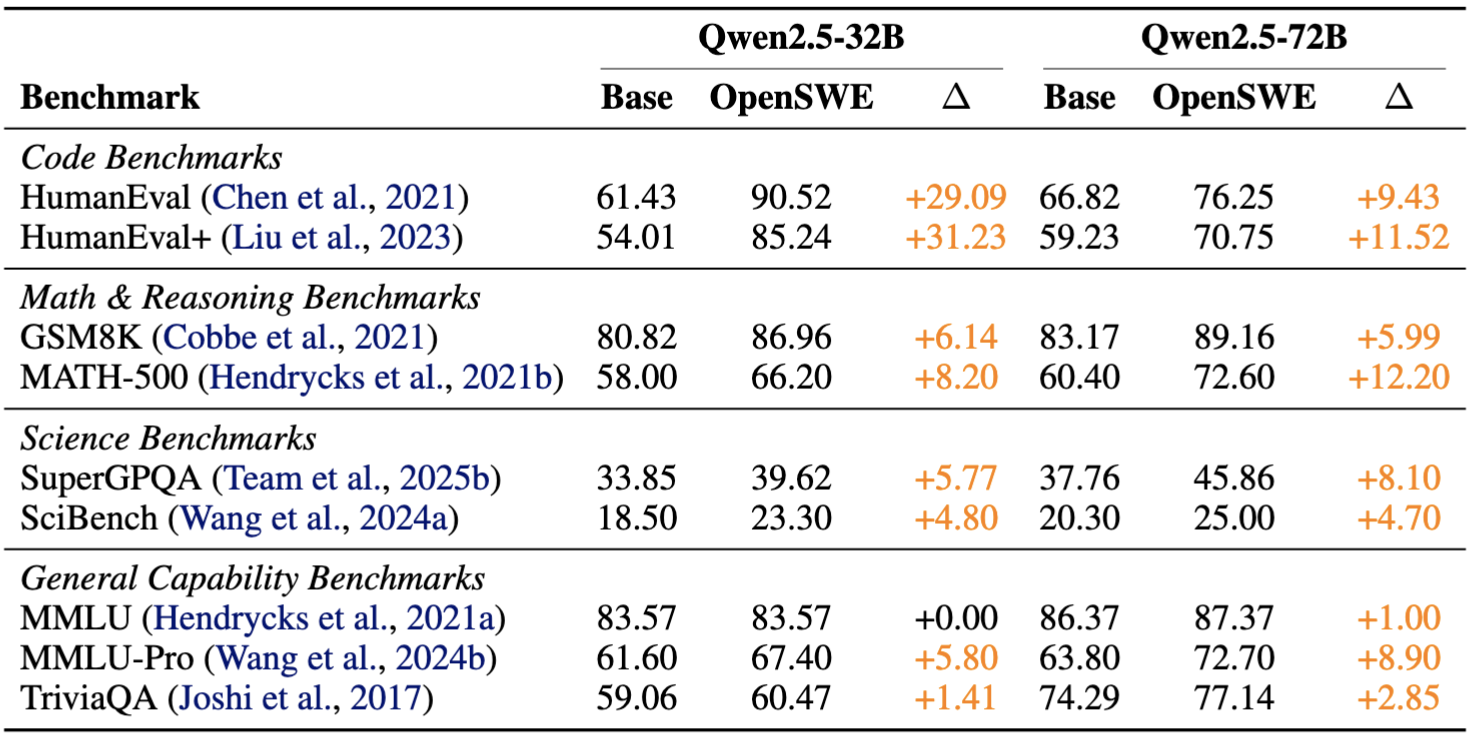
基础模型与OpenSWE模型的通用能力对比
过去,很多最强的智能体能力都掌握在封闭系统手里。大家能看到结果,却看不到过程;能看到分数,却复现不了基础设施。OpenSWE的真正价值,在于它试图把这堵墙拆掉一部分。它告诉开源社区:大规模、真实、可执行、可验证的软件工程环境,不一定只能由少数巨头垄断;环境合成这件事,也不再只是“工业秘密”,而可以成为一个被复现、被扩展、被共同建设的公共基础设施。这也是为什么我们更愿意把OpenSWE看成一个信号,而不只是一篇论文。在智能体时代,决定上限的,不只是模型参数,不只是推理token,也不只是后训练技巧。谁能规模化生产高质量环境,谁就更可能掌握下一轮智能体演化的主动权。而今天,我们要做的,是把这把钥匙,第一次比较完整地交到了开源社区手里。
Paper:https://arxiv.org/pdf/2603.13023
Code:https://github.com/GAIR-NLP/OpenSWE
Dataset:https://huggingface.co/datasets/GAIR/OpenSWE
