
近日,来自上海创智学院、复旦大学和中国科大等机构的研究团队联合发布了轻量级统一多模态模型 DeepGen 1.0。 仅用 5B 参数(3B VLM + 2B DiT),DeepGen 1.0 将图像生成、图像编辑、推理生成、推理编辑、文字渲染五大能力集成在一个模型中,并在多个权威 benchmark 上与体量大它 3 到 16 倍的模型展开竞争,多项指标上实现了超越。
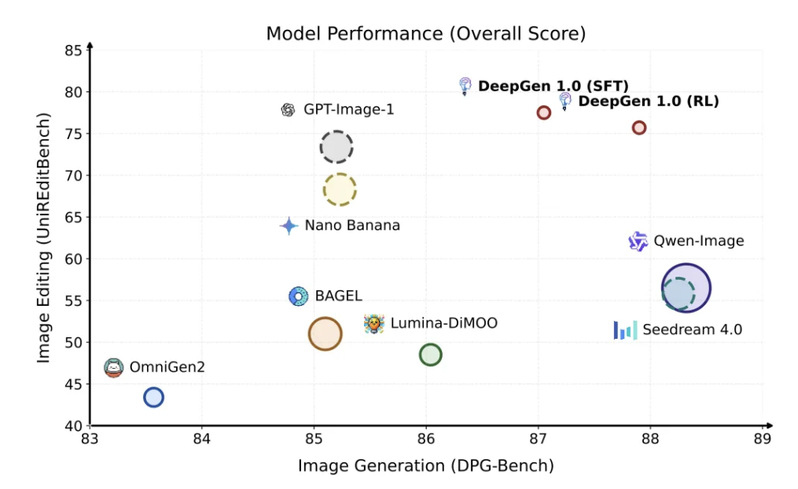
在生成任务上,DeepGen 1.0 在 GenEval、DPGBench、UniGenBench 三个 benchmark 上均达到领先水平,接近甚至超过参数量数倍于它的模型;在编辑任务上,ImgEdit 和 GEdit-EN 同样表现出色,且生成与编辑由同一个模型完成,无需单独部署。在推理相关的任务上表现尤为突出:WISE(世界知识推理生成)得分 0.73,比 80B 的 HunyuanImage 3.0 高出 28%;UniREditBench(推理编辑)得分 77.5,比 27B 的 Qwen-Image-Edit 高出 37%。
·论文标题:DeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing
·论文链接:https://arxiv.org/pdf/2602.12205
·代码地址:https://github.com/deepgenteam/deepgen
·模型权重:https://huggingface.co/deepgenteam/DeepGen-1.0

一、行业痛点:统一多模态大模型的“规模焦虑”
要让图像生成和编辑能处理越来越复杂的指令,模型就不能只停留在像素合成层面,还需要具备深层的语义理解能力。为此,一种将视觉语言模型(VLM)的理解能力与扩散模型的生成能力相结合的范式逐渐成为主流方向。GPT-Image-1 和 Gemini 等闭源系统已经验证了这条路线的可行性,开源社区也在快速跟进,BAGEL、Qwen-Image、HunyuanImage 3.0、LongCat-Image 等一系列模型接连涌现。
但有一个问题:这些模型都太大了。
Qwen-Image 部署需要 27B 参数,HunyuanImage 3.0 更是达到了 80B,LongCat-Image 要 13B,BAGEL 有 14B。更关键的是,不少模型还要分别部署独立的生成和编辑模型,实际参数量翻倍。比如 Qwen-Image 和 Qwen-Image-Edit 一共需要部署 54B 参数量。
训练成本同样惊人。HunyuanImage 3.0 用了 50 亿训练样本,LongCat-Image 用了 12 亿。对大多数团队来说,这样的资源门槛几乎不可能跨越。
DeepGen 1.0 给出了一个不同的思路:通过精巧的 VLM-DiT 桥接架构(SCB)、高质量的多任务数据编排、以及用 MR-GRPO 框架将 RL 训练稳定 scale up 到 1500 步,仅用 5B 参数和约 5000 万训练样本,就在推理生成和推理编辑上达到了领先水平。
二、核心创新
2.1 整体架构:VLM-DiT 双塔
DeepGen 1.0 沿用了当前主流的 VLM-DiT 范式,但做了一个很克制的选择:用 Qwen-2.5-VL(3B)做理解和推理的底座,用 SD3.5-Medium(2B)做生成的底座。两者加起来总共 5B 参数。
VLM 负责处理文本和图像输入,提供丰富的多模态语义理解;DiT 作为生成解码器,在 VLM 提供的多模态条件引导下生成高质量图像。两者之间通过一个精简的 encoder based connector 模块进行特征对齐。
整体设计理念很明确:不堆参数,靠"桥"搭得好。
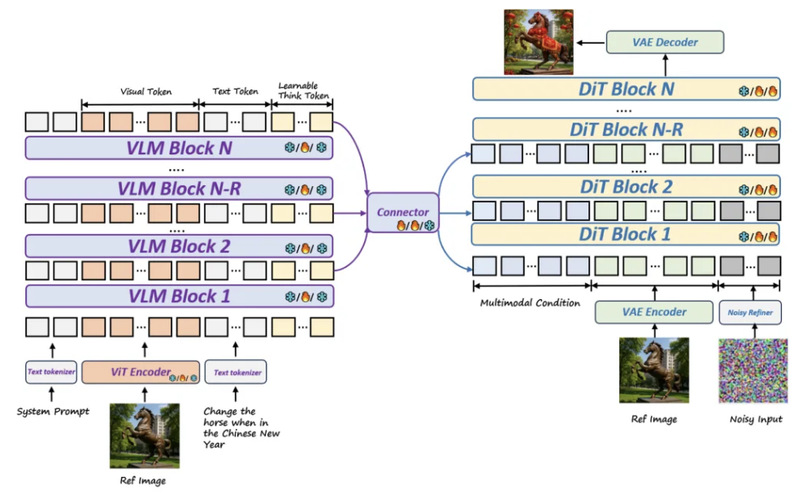
2.2 架构创新:堆叠通道桥接(SCB)
VLM 和 DiT 之间如何传递信息,是统一多模态模型的一个核心设计决策。
过去大多数模型的做法很简单:取 VLM 最后一层(或倒数第二层)的隐状态,通过 connector 变换后送给 DiT。但这有两个问题:
第一,信息丢失。VLM 的最后几层高度偏向语义抽象,细粒度的视觉细节在这个过程中被大量丢弃,而这些细节恰恰是 DiT 生成高质量图像所需要的。
第二,表示偏差。只依赖单一层的信号,容易受到该层特定表示偏差的影响,不利于 VLM 和 DiT 之间的稳定对齐。
也有一些工作尝试在 VLM 和 DiT 之间做深度融合(比如 shared attention),但这会大幅增加参数量和训练复杂度。还有用平均池化聚合多层特征的,但平均池化会模糊细粒度信息。
DeepGen 提出的堆叠通道桥接(Stacked Channel Bridging, SCB) 走了一条折中路线:
1.层选择:从 VLM 的低、中、高层均匀采样 6 个隐状态层,捕获不同粒度的特征
2.通道拼接 + 投影:将多层隐状态沿通道维度拼接,再通过轻量级 MLP 投影到 DiT 的输入维度
3.Transformer 融合:投影后的特征送入 Transformer encoder connector,跨层融合信息
在 SCB 之上,DeepGen 还引入了 Think Tokens,即 128 个可学习的 token,拼接在文本 token 之后。这些 token 充当隐式的思维链(Chain of Thought),帮助模型在面对复杂推理指令时"先想再画"。
消融实验也验证了这两个设计的效果。去掉 SCB 后,DPGBench 从 87.05 降到 85.55,WISE 从 0.72 降到 0.70;去掉 Think Tokens 后,WISE 从 0.72 直接掉到 0.68,RISE 从 13.3 掉到 11.7。Think Tokens 对推理任务的提升尤为明显。
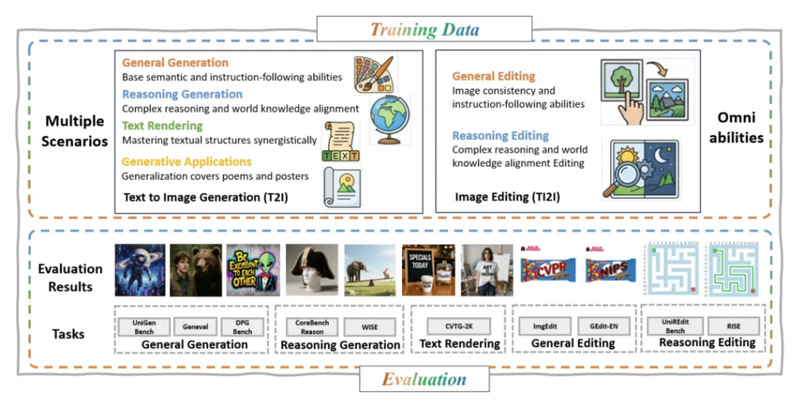
2.3 训练策略:三阶段渐进式训练
DeepGen 采用了三阶段的渐进式训练策略,核心思路是"先对齐,再联调,最后用 RL 提纯":
·Stage 1 - 对齐预训练:只训练 connector 和 128 个 Think Tokens,其他参数全部冻结,让 VLM 的表示空间和 DiT 的潜空间先对齐
·Stage 2 - 联合 SFT:解冻 DiT,同时对 VLM 施加 LoRA 做端到端联合训练,在一个涵盖通用生成/编辑、推理生成/编辑、文字渲染的多任务混合数据上进行优化
·Stage 3 - 强化学习:用 MR-GRPO 进一步优化,使用 1500 步混合奖励和监督学习稳步提升可视化效果和人类偏好对齐,
数据效率方面同样值得关注:整个训练只用了约 5000 万样本。作为对比,LongCat-Image 用了 12 亿,HunyuanImage 3.0 用了 50 亿,差距接近两个数量级。
2.4 强化学习:MR-GRPO
在 SFT 之后,DeepGen 引入了 MR-GRPO(Multi-Reward Group Relative Policy Optimization)做强化学习阶段。MR-GRPO 是 Pref-GRPO 的一个变体,把 GRPO 扩展到了 flow matching 模型,核心特点是混合使用 pointwise 和 pairwise 奖励模型来评估生成图像。
在此基础上,MR-GRPO 采用了两项已有的改进:噪声保持随机采样策略(产生更干净的样本和更准确的奖励信号)和解耦优势归一化(更好地保持多奖励信号的粒度)。
奖励设计方面,MR-GRPO 使用三种互补的奖励函数:VLM pairwise 偏好奖励(评估图文对齐和视觉质量)、OCR 奖励(优化文字渲染准确度)、CLIP 相似度(衡量整体语义一致性),并针对不同类型的任务数据设置不同的加权权重。
此外,DeepGen 还提出了辅助 SFT 损失 (Auxiliary SFT Loss)来解决 RL 训练中的能力退化问题。
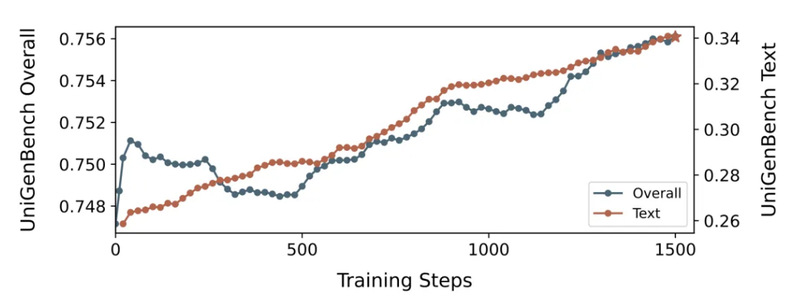
这个问题是这样的:RL 训练通常用 KL 散度正则化来防止策略偏离参考模型。但 DeepGen 团队发现,KL 正则化单独使用是不够的。当 RL 训练超过约 1000 步后,模型在需要复杂指令理解的任务(如推理生成)上出现明显的性能下降。
原因不难理解:KL 正则化只是"惩罚偏离",告诉模型"不要走太远",但没有提供"正向引导",不会告诉模型"好的生成长什么样"。
所以 DeepGen 引入了一个辅助的监督扩散损失 L_SFT,在 RL 训练过程中持续锚定模型到 SFT 阶段学到的分布。最终训练目标变为:
L_total = (1 - λ) · L_GRPO + λ · L_SFT
消融实验验证了这一点:去掉辅助 SFT Loss 后,模型在大约 300 步后性能开始崩塌,最终跌到远低于初始 checkpoint 的水平。KL 正则化和辅助 SFT Loss 的组合提供了互补的约束:KL 惩罚偏离,SFT Loss 提供正向引导,两者缺一不可。
三、实验结果
DeepGen 1.0 在通用生成与编辑、推理生成、推理编辑等多个维度上做了全面评测。以下按任务类型展开。
3.1 通用生成与编辑
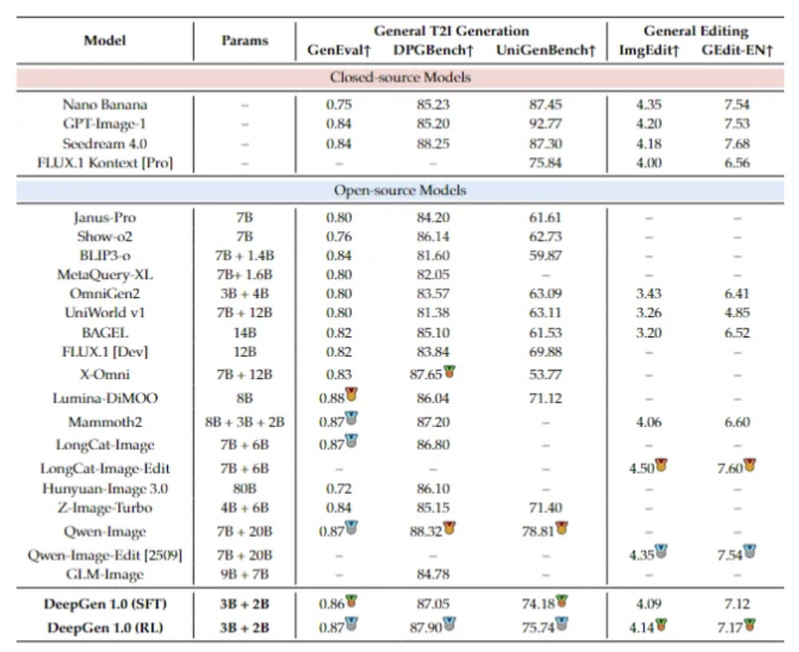
在通用生成任务上,DeepGen 1.0(RL)用 5B 参数交出了这样的成绩单:
·GenEval 0.87,与 27B 的 Qwen-Image 和 13B 的 LongCat-Image 持平
·DPGBench 87.90,超过 80B 的 HunyuanImage 3.0(86.10)
·UniGenBench 75.74,超过 LongCat-Image、HunyuanImage 3.0 等更大的商业级开源模型
在编辑任务上,DeepGen 1.0 同样保持竞争力,ImgEdit 4.14、GEdit-EN 7.17,而且这是同一个模型同时做生成和编辑,不需要像 Qwen-Image 和 LongCat-Image 那样单独部署编辑模型。
5B 参数的模型,生成和编辑同时覆盖,各项 benchmark 表现领先,参数效率上的优势非常明显。
3.2 推理生成
推理生成是 DeepGen 1.0 表现最突出的方向。
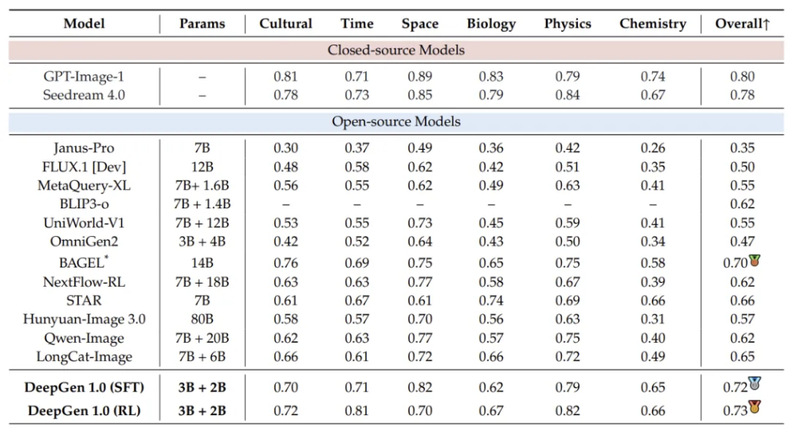
WISE(世界知识推理生成)上,DeepGen 1.0(RL)拿到0.73,在开源模型中处于领先位置。与其他更大的开源模型对比:
·80B 的 HunyuanImage 3.0 仅为 0.57,DeepGen 领先 28%
·14B 的 BAGEL(依赖显式 CoT 推理)得分 0.70
·7B+20B 的 Qwen-Image 为 0.62
一个 5B 参数的模型,在推理生成上超越了参数量大自己 16 倍的对手。
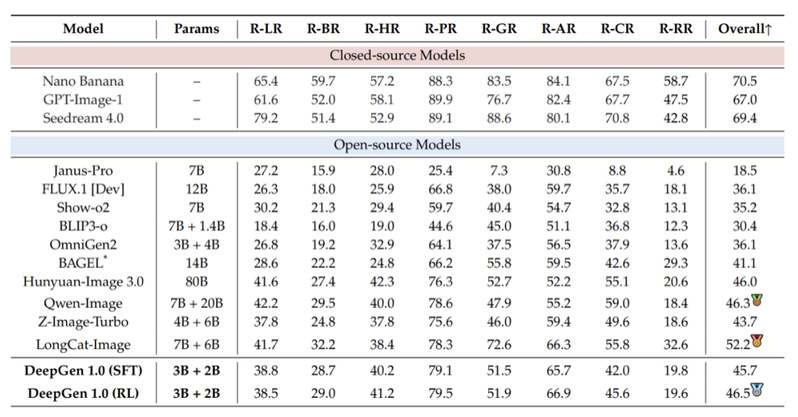
在 T2I-CoREBench 的reason set(覆盖 8 类推理维度)上,DeepGen 1.0(RL)得分 46.5,超过 Qwen-Image(46.3)和 80B HunyuanImage 3.0(46.0)。
3.3 推理编辑
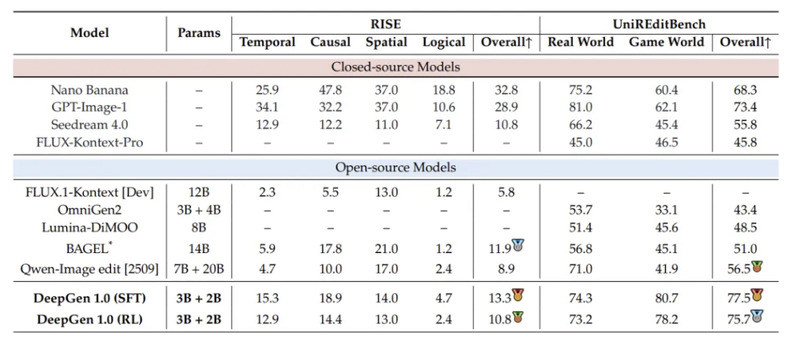
推理编辑同样是 DeepGen 的强项:
·RISE:SFT 版本拿到 13.3,超过 BAGEL 的 11.9 和 Qwen-Image-Edit 的 8.9
·UniREditBench:SFT 版本 77.5,RL 版本 75.7,大幅领先 27B 的 Qwen-Image-Edit(56.5),领先幅度达 37%
3.4 消融实验

RL 阶段的消融实验进一步验证了 MR-GRPO 各组件的作用:
·去掉辅助 SFT Loss:UniGenBench 整体从 75.69 跌到 74.33(-1.36),文字渲染得分从 35.06 跌到 33.33(-1.73)。从训练曲线看,约 300 步后性能开始持续下降
·去掉 KL 正则化:DPGBench 从 87.75 降到 87.32(-0.43),文字渲染从 35.06 降到 32.47(-2.59)
·去掉 Reward-wise 归一化:文字渲染得分从 35.06 降到 32.18(-2.88),说明高方差的奖励信号会主导策略更新,阻碍特定目标的优化
三个组件各有分工,但辅助 SFT Loss 对训练稳定性的影响最为关键。
四、总结
DeepGen 1.0 证明了一件事:在统一多模态模型上,参数量不是唯一的答案。
通过 SCB 架构的多层特征桥接、Think Tokens 的隐式推理增强、三阶段渐进训练、以及 MR-GRPO 的混合奖励强化学习,一个 5B 参数的模型做到了在推理生成和推理编辑上领先,同时在通用生成和编辑上保持竞争力。
同时,上海创智学院团队选择了全面开源,代码、模型权重、关键数据集全部公开。这意味着研究者不需要动辄数百 GPU 的集群,也能基于这个框架做进一步的探索。
从技术趋势来看,轻量化 + 精巧设计的路线在统一多模态领域还有很大的探索空间。
