
智能体长程任务的马拉松哲学:不只要"做对",更要"持续做对"——而这种能力,藏在GitHub的项目演化史里。
一、引言:智能体也需要"耐力训练"
在AI智能体的世界里,解决问题就像跑步。回答一个问题,是百米冲刺;而开发一个完整的软件功能,则是一场马拉松。当前的大语言模型在"短跑"上已经游刃有余——写个函数、回答个问题,几秒钟就能搞定。但一旦进入需要持续规划、反复迭代、跨阶段协调的"长跑"任务(长程任务,Long-horizon Task),它们往往会迷失方向:忘记初始目标、陷入死循环、遇到错误就"装死"。
这个问题的根源在哪里?缺少合适的"马拉松教练"。
传统的AI训练方法,要么依赖海量的合成数据(但这些数据像在跑步机上训练,缺乏真实路况的复杂性),要么依靠昂贵的人工标注(一个样本可能需要专家花费数小时)。这两种方法都难以规模化地提供"长距离、多阶段、有反馈"的真实训练场景。
来自创智学院(SII)与上海交通大学GAIR实验室的研究团队,找到了一个答案:最好的马拉松教练,就藏在GitHub的Pull Request历史里。
他们提出的"达芬奇·能动"(daVinci-Agency)框架,用239个精心挖掘的"代码演化样本",击败了基于66,000个传统样本训练的模型——在关键基准测试Toolathlon上实现了148%的性能飞跃,同时还减少了13.3%的工具调用次数。目前,daVinci-Agency 的模型权重、训练数据集及构建工具链代码均已在 Hugging Face 与 GitHub 同步开源。
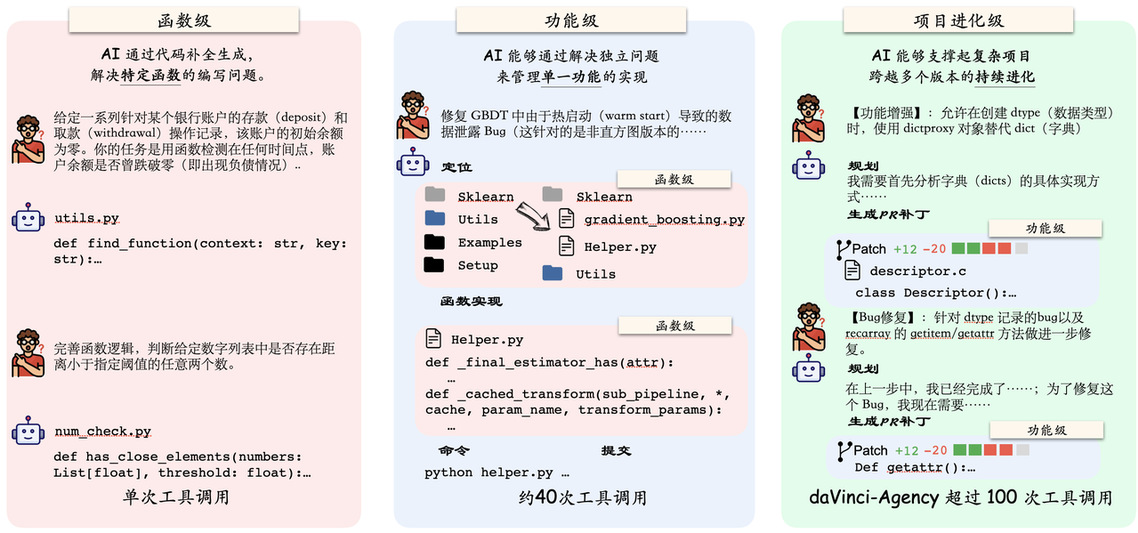
这是长程智能体训练新范式:不靠数据量,靠数据完整性,与其让智能体在跑步机上反复冲刺,不如让它在真实赛道上完整体验一次马拉松的节奏、策略与坚持。
二、核心发现:GitHub Pull Request(PR)链是天然的"长跑训练场"
研究团队提出的"达芬奇·能动"框架,基于一个简单而深刻的洞察:
| 软件开发的Pull Request演化过程,天然包含了长程任务所需的全部训练信号。
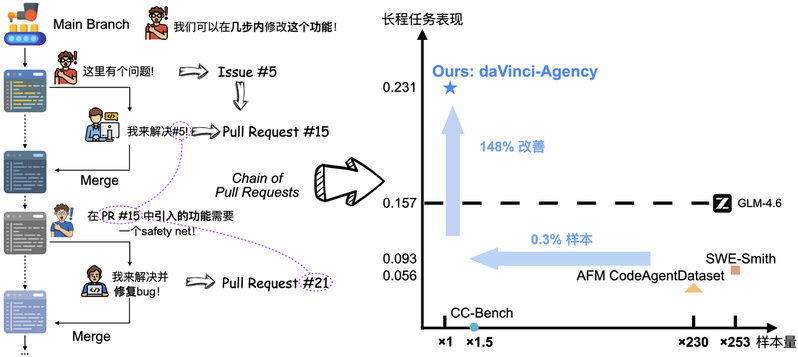
在 GitHub 上,一个功能的实现往往不是一蹴而就的,而是由一系列有先后依赖关系的 Pull Request(PR 链)组成的。团队敏锐地捕捉到,这种天然的 PR 序列恰恰包含了训练长程智能体所需的所有核心信号:
·任务分解的艺术:每一个 PR 都是复杂目标的阶段性产物。
·长程一致性的约束: 多个 PR 必须共同服务于一个最终的工程目标。
·真实纠错的轨迹: 后面的 PR 往往是在修复前一个 PR 引入的 Bug 或缺陷 。
通过这种“Chain of PR”模式,daVinci-Agency 自动构建出了具备超过最长超过3百万 Tokens、平均 116 次工具调用的“地狱级”训练轨迹。
更重要的是,这些训练数据完全来自真实世界,无需合成、无需标注,且自带质量验证(通过代码审查和测试)。
三、惊人的效率:239个样本 vs. 66,000个样本
"达芬奇·能动"最令人震撼的结果是其数据效率,实验结果表明,在这一范式的加持下,数据的“质”超过了“量” :
·极高的效率: 仅仅在 239 个 daVinci-Agency 样本上进行微调,GLM-4.6 在 Toolathlon 上的性能就实现47%相对提升的爆发式增长,并呈现出在不同架构模型上的良好泛化
·超越“巨无霸”: 相比之下,使用传统方法生成的 6.6 万条数据(SWE-Smith)在长程任务上的表现显著低于 daVinci-Agency 的少量精锐数据。
·跨越领先: 通过在daVinci-Agency样本上的微调,使得GLM-4.6在Toolathlon上超越了原本更优秀的模型Kimi-K2-Thinking。
 图注:和不同agentic数据集微调效果的对比,同时通过singlepr和temporal chain的消融实验,我们在多个长程任务benchmark上展现了显著的性能优势
图注:和不同agentic数据集微调效果的对比,同时通过singlepr和temporal chain的消融实验,我们在多个长程任务benchmark上展现了显著的性能优势
 图注:在不同模型上微调的对比,我们成功超越了比基模更优秀的开源模型
图注:在不同模型上微调的对比,我们成功超越了比基模更优秀的开源模型
为什么这么高效?
传统方法的问题在于,即使有百万级样本,如果每个样本都是"孤立的短跑",模型永远学不会"马拉松"的节奏。
daVinci-Agency的样本虽少,但每个样本都是一次完整的长距离训练:
·平均85k tokens(相当于一本中篇小说的长度)
·平均116次工具调用(需要持续的规划和执行)
·跨越多个开发阶段(从初始实现到bug修复)
这就像,与其让运动员跑一万次百米,不如让他完整地跑几次全程马拉松——后者对"长跑能力"的锻炼效果更好。
四、技术解密:如何从GitHub挖掘"黄金训练数据"
daVinci-Agency的数据构建流程分为三个阶段:
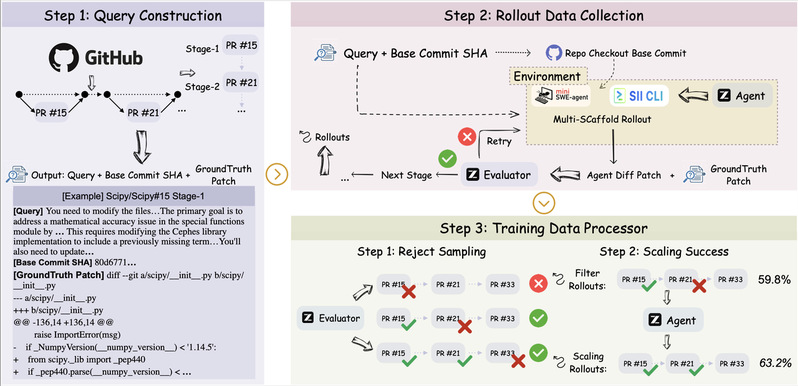
-阶段一:PR链挖掘
团队从9个代表性开源项目(numpy、scipy、apache/pulsar等)中精选了61,810个PR,覆盖Python、Java、Rust、C等多种语言栈。
关键创新在于语义依赖图构建:不是简单按时间排序,而是通过commit message和review comments中的引用关系,重建真实的功能演化拓扑。例如:

这种链式结构保证了训练任务具有真实的跨阶段依赖。
-阶段二:意图化查询生成
对每个PR链,使用LLM提炼出"意图驱动的查询"。关键是:
·只描述目标(Why),不泄露具体实现(What)
·指明概念位置(Where),但不给出代码路径
·抽象关键逻辑(How),但不写出具体步骤
这迫使AI在执行时必须主动探索、定位代码、理解上下文——就像真实开发者面对新任务一样。
-阶段三:高质量轨迹收集
使用两个并行的执行脚手架(SII-CLI和mini-swe-agent),让GLM-4.6模型在真实代码库中执行任务。
核心机制——拒绝采样:
·使用严格的评估器(阈值≥0.8)过滤低质量轨迹
·对不合格样本给予反馈,允许最多3次改进
·最终只保留语义对齐的高保真数据
实验验证:没有拒绝采样时,模型性能暴跌至0.205(远低于基线的0.405);加入拒绝采样后,性能跃升至0.421。这证明数据质量是决定性因素。
五、行为分析
1.AI真的学会了"长跑"吗?
研究团队对模型的实际执行轨迹进行了深入的定性分析,发现了令人惊喜的行为模式。

案例:Django Issue #11149(权限bug修复)
基线模型的表现:
·目标漂移:在无关模块(admin_views)中徘徊多个回合
·逃避主义:遇到配置错误就转而编写简化脚本,不解决根本问题
·缺乏规划:直接尝试运行测试,没有先建立测试环境
daVinci-Agency模型的表现:
·结构化分解:先配置环境,再按从通用到具体的顺序执行测试序列
·主动反思:在代码修改过程中暂停,发现潜在bug:"等等,我发现了一个问题...这里调用self会导致无限递归"
·预防性修复:主动使用super()方法规避递归问题,在运行前就解决了错误
这种"aha moment"式的自我纠错,正是人类专家级开发者的典型特征——在daVinci-Agency训练后,AI首次展现出了类似的能力。
2.数据扩展的“天梯”:Training Horizon Scaling与 Test Scaling
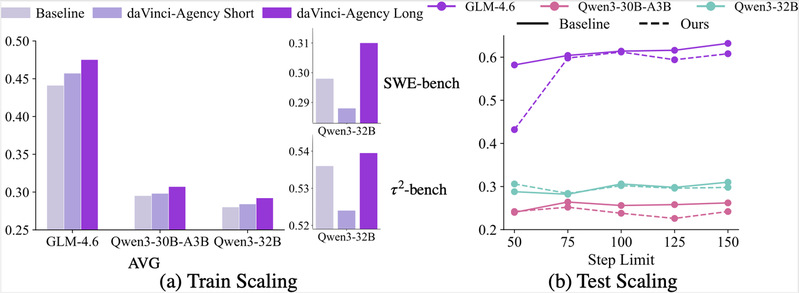
我们研究了如何通过扩展交互轨迹的长度来持续突破性能天花板:
·Training Horizon Scaling(训练时扩展):通过将训练轨迹从 59k Token(Short)扩展至 85k Token(Long),模型在 SWE-bench 和 $\tau^2$-bench 上的性能获得持续增益。这证明了交互轨迹的长度本身就是增强问题解决能力的有效扩展维度。
·Test-time Compute Scaling(测试时扩展):在推理阶段,随着允许的工具调用上限(Step Limit)增加,daVinci-Agency 模型的优势显著扩大。它展现了卓越的推理韧性,能够有效消化更多推理预算而不崩溃,维持稳定的长程解决能力。
3.极致智能密度

更聪明的 Agent 往往更懂得“精准出击”。对于daVinci-Agency 训练之后的模型,其成功完成任务所需的 Token 消耗大幅减少(如 Qwen3-32B 减少了 288.8k),工具调用效率提升最高达 25.8%。这表明 daVinci-Agency 赋予了模型内化的规划技能,使其能修剪冗余动作,实现“智能密度”的提升。
六、结语:智能体的"马拉松时代"已经到来
长期以来,AI智能体社区专注于提升模型在单一任务上的"冲刺速度"。但真正的智能,需要的是在复杂、动态、长周期任务中保持方向感和适应力的"马拉松耐力"。
daVinci-Agency的核心贡献,不仅仅是一个性能更好的训练方法,更是一种智能体长程智能训练范式转变:
| 从"合成海量样本"到"挖掘真实演化";
| 从"追求数据规模"到"重视结构质量";
| 从"孤立任务训练"到"全周期闭环学习"。
这个藏在GitHub里的"马拉松教练",用239个样本证明了:
教AI学会长跑,不需要让它跑一万次百米——只需要让它完整地跑几次全程马拉松,并在每个阶段都得到真实的、演化的反馈。
智能的上限由数据的深度决定。
当智能体能够从人类软件开发过程中的迭代、纠错与重构逻辑中汲取智慧,它们才真正具备了处理复杂现实世界工程事务的能力。从 daVinci-Agency 开始,智能体 将跨越短任务的舒适区,奔向百万 Token 的长征。
论文标题: daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently
论文链接:https://github.com/GAIR-NLP/daVinci-Agency/blob/main/asset/daVinci-Agency.pdf
GitHub 链接: https://github.com/GAIR-NLP/daVinci-Agency
Huggingface数据集链接:https://huggingface.co/datasets/GAIR/daVinci-Agency
Huggingface模型链接:https://huggingface.co/GAIR/daVinci-Agency
