
在推理(Reasoning)时代,Mid-training(中期训练)还只是"锦上添花";到了Agent时代,Mid-training从"锦上添花"变成了"不可或缺"。
这是刘鹏飞团队在深度实践Agent开发后得出的核心洞察。当整个行业还在用Post-training(后训练)和强化学习(RL)刷榜、蒸馏、修补问题时,他们已经把目光投向了更深层的Mid-training层。在Agent时代,Post-training(后训练)优化表现,Mid-training(中期训练)构建能力——没有充分的能力基建,再多的Post-training也只是在有限空间内的局部优化。
来自创智学院 & 上海交通大学 GAIR团队发布全球首个全面开源的Agentic Mid-training解决方案和开源Agentic模型daVinci-Dev(达芬奇),还包含完整的数据构建方法、训练策略、百亿token数据集等。这个被称为"Agent时代胜负手"的训练阶段,终于有了可复现的最佳实践。
一、为什么Mid-training在Agent时代变得如此关键?
1.Agent时代的能力需求,已经超出了Post-training的能力边界
在传统的单轮对话或推理任务中,模型需要的是单一能力的纵深——把推理做到极致,把对话做得流畅。但在Agent场景下,模型面对的是多能力的动态编排:一个完整的软件开发任务,可能需要串联代码定位、bug诊断、测试生成、工具调用、上下文管理等10+种能力,每个环节都可能触发不同的子任务分支。
这种能力复杂度的跃迁,给Post-training带来了巨大的麻烦。
Post-training的逻辑是:在预训练模型已有的能力边界内,通过人类(或AI)反馈、强化学习等方式优化表现。它可以让模型更好地"对齐"人类(AI)偏好,可以纠正特定错误模式,但它无法凭空创造模型不曾见过的能力项。
更致命的是,长链条任务的容错率极低。在一个包含20步的开发流程中,每步成功率95%,最终成功率只有35%。任何一个环节的能力缺失,都可能导致整个任务失败。Post-training擅长修补"已知问题",但面对"未知的能力缺口"——比如从未学过的"工具调用后的异常处理",再多的Post-training也无济于事。
这就是为什么顶级模型在某些Agent任务上会集体"卡壳":不是它们不够聪明,而是缺少了关键的能力基建。而这些能力基建,必须在Mid-training阶段通过大规模、高复杂度的长链条数据来构建。
2.现有训练数据的根本性缺陷:分布偏差
目前的开源代码模型,大多是用GitHub上的代码数据训练出来的。但这里有一个巨大的分布偏差(Distribution Mismatch)。
GitHub上的代码(Pull Request),通常是静态的"快照":它告诉你"结果是什么",却没告诉你"过程是怎么来的"。
·它没记录开发者为了改这行代码,翻看了哪三个相关文件(Context);
·它没记录开发者第一次改错了,看了什么报错信息(Traceback),才修正成最终版本;
·它没记录开发者如何在测试失败后,迭代修正代码直到通过。
用静态的结果去训练动态的Agent,就像是给想学开车的人看了一万张"汽车停在车库里"的照片,却从来不带他上路。
刘鹏飞团队提出:要训练真正的Agent,必须使用Agent-Native Data(智能体原生数据)。我们需要在Mid-training阶段,就让模型"体验"真实的开发流程。
二、Agent-Native Data:还原“思考”与“体感”
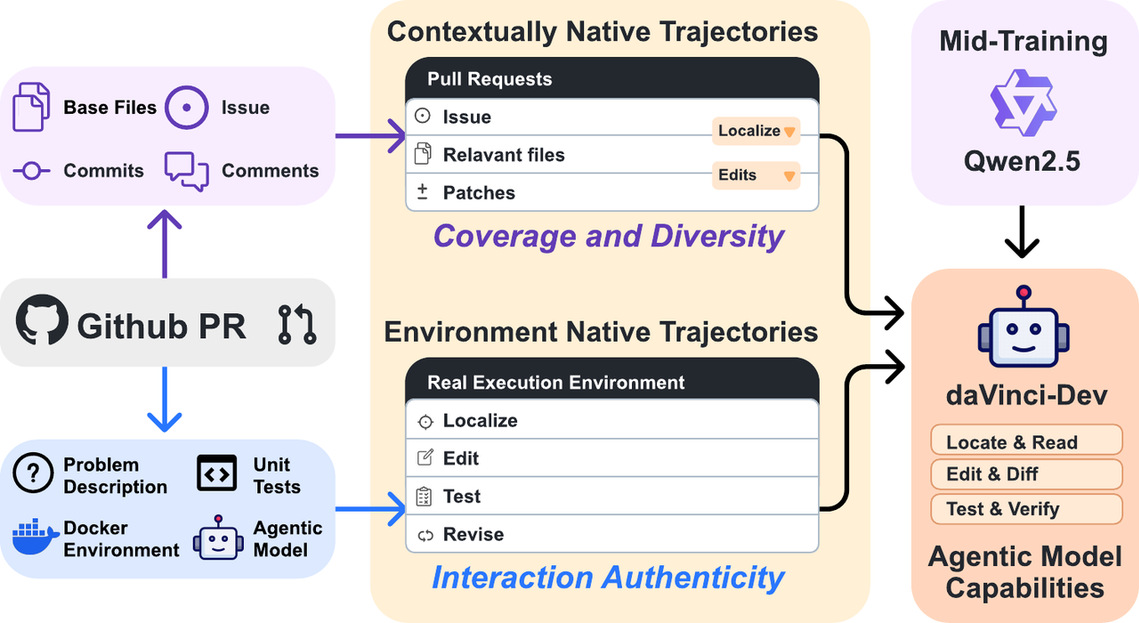
为了填补这一鸿沟,构建了两类核心数据,重塑了模型对软件工程的认知:
1. Contextually-native Trajectories(上下文原生轨迹,686亿token):还原"思考流"
不仅仅是代码补全。团队从1000万+真实GitHub PR中,重构了代码变更背后的完整程序化过程。
关键创新:Bundle Everything Together(捆绑一切上下文)
·模拟定位: 模型需要学习开发者是如何在几百个文件中找到由于依赖关系需要修改的那一个;
·模拟推理: 还原开发者“阅读 Issue -> 分析现有代码 -> 构思修改方案”的完整心路历程。
·这让模型不再是“盲写”,而是学会了先看后写(Navigation before Editing)。
2. Environmentally-native Trajectories(环境原生轨迹,31亿token):还原"真实体感"
这是最残酷但也最有效的一环。团队在2万个真实Docker环境中部署Agent,让它"真刀真枪"地干活。
关键创新:Real Execution Loop(真实执行循环)
·真实交互: 调用 Linter,运行 Unit Tests,拿真实的 Build System 交互。
·真实反馈: 模型看到的不是人工构造的完美数据,而是真实的 Runtime Error。它必须学会根据报错去自我修正。
·这赋予了模型“自我反思”的本能。
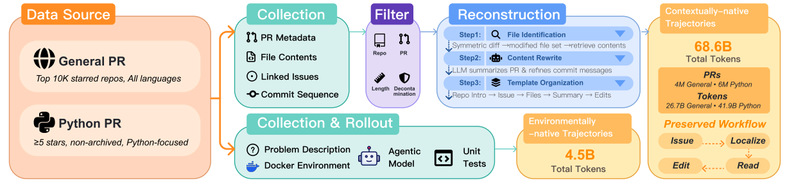
两类数据的协同效应:1+1>2
团队的实验揭示了一个关键发现:两类数据形成互补,缺一不可。
这说明:
·PR数据提供"知识和广度":跨语言、跨框架的软件工程模式,让模型见识足够多的"什么样的问题对应什么样的解决思路";
·环境轨迹提供"深度和真实性":动态交互和反馈循环,让模型习得"如何在不确定环境中迭代求解"。
就像学开车:PR数据是"科目一理论学习",环境轨迹是"科目三实际上路"。两者结合,才能培养出真正的Agent。
三、 实验结果:以小博大,效率倍增
基于 Qwen 2.5 Base 模型进行了验证,结果令人振奋:配方(Recipe)的重要性,甚至超越了单纯的数据堆砌。
1.效率的胜利:数据减半,性能反超
相比于此前开源界最先进的 Kimi-Dev 训练配方,我们仅使用了其 50% 的数据量(73.1B vs ~150B tokens),就在两种后训练方式均下实现了性能反超。这说明,Agent-Native 数据的“含金量”远高于普通的合成数据。
2.跨代际的打击
在 SWE-Bench Verified(公认的真实软件工程评测)上,我们的 daVinci-Dev-72B 和daVinci-Dev-32B 模型分别达到了 58.5% 和 56.1% 的解决率。
更值得注意的是,在 Agentic Scaffold(智能体框架)下,该模型的表现超越了目前基于 Qwen 2.5 Coder 甚至 Qwen 3 的开源训练方案。
这揭示了一个深刻的道理:与其盲目追求更新的基座,不如用更符合 Agent 本能的数据去重塑现有的模型。
Image
 图注:在 SWE-Bench Verified上的消融实验和中期训练对比。我们在上下文原生轨迹和环境原生轨迹上进行的智能体中期训练持续提升了下游任务性能,并且与先前的中期训练方案相比具有竞争力或表现更优。
图注:在 SWE-Bench Verified上的消融实验和中期训练对比。我们在上下文原生轨迹和环境原生轨迹上进行的智能体中期训练持续提升了下游任务性能,并且与先前的中期训练方案相比具有竞争力或表现更优。
 图注:我们的模型在智能体框架下的表现超越了目前基于 Qwen 2.5 Coder 甚至 Qwen 3 的开源训练方案。
图注:我们的模型在智能体框架下的表现超越了目前基于 Qwen 2.5 Coder 甚至 Qwen 3 的开源训练方案。
3.能力的泛化:Agent思维的溢出效应
虽然团队专注于软件工程,但Agent的决策和规划能力展现出了惊人的迁移性(科学推理、科学计算),这说明,在Agent化过程中习得的"定位-推理-行动-反思"范式,本身就是一种通用的问题解决能力,可以迁移到其他需要多步推理的领域。模型在Mid-training中学到的不只是"如何写代码",更是"如何分解问题、寻找信息、验证假设、迭代优化"——这是Agent的底层操作系统。
四、 结语:从可能到普惠
上海创智学院一直秉持着**“从不可能到可能,从可能到价值,从价值到普惠”**的愿景。
·从不可能到可能: 我们证明了 Agent 的核心能力(自主定位、环境交互、多步推理)并非只有闭源巨头才能掌握,它是可以通过特定的 Mid-Training 注入到开源模型中的。
·从可能到价值: 58.5% 的 SWE-Bench 分数,意味着开源模型在真实软件工程任务中已具备极高的实用价值。
·从价值到普惠: 这是我们今天最重要的一步。
虽然闭源模型(如 GPT-5.2)依然强大,但技术的护城河不应成为阻碍创新的高墙。我们决定开源这套 Agentic Mid-Training 的完整配方。
今天,我们将正式公开:
·🚀 数据构建代码: 如何从静态 PR 中提炼 Agent-Native 数据的工具;
·⚙️ 训练配置(Configurations): 复现我们实验的完整参数;
·📂 精选数据集与模型权重: 供社区直接使用和微调。
在Agent时代,Mid-training是胜负手。今天,这个胜负手不再是秘密,而是所有人都能掌握的武器。
我们希望通过解密这套配方,让开源社区的 Agent 进化之路,少走两公里的弯路。
Paper: https://github.com/GAIR-NLP/daVinci-Dev/blob/main/daVinci-Dev.pdf
Code: https://github.com/GAIR-NLP/daVinci-Dev
Dataset: https://huggingface.co/datasets/GAIR/daVinci-Dev
Model: https://huggingface.co/GAIR/daVinci-Dev-72B
