
创业遇到挫折,你想听听马斯克的建议时,他就在那里——"失败代表着迭代。没有爆炸般的失败,哪来的创新?Keep going."
当你心情低落想找偶像聊天时,屏幕上不再是冰冷的文字框——坤坤的身影实时浮现,带着温暖的笑容对你说:"别难过了,给自己多一点时间。"
失恋那天,你问AI该怎么办时,回应你的不是一段生硬的建议——霉霉出现在屏幕上,眼神真挚,语气温柔:"你已经很棒了。走出来很难,先允许自己难过一会儿。"
这是上海创智学院深度认知智能标杆项目刘鹏飞团队 & 上海交通大学刚刚开源的LiveTalk系统带来的真实体验。
与GPT-4o、Gemini等AI助手不同,LiveTalk不仅能听懂你、理解你、回答你,还能以实时生成的虚拟化身与你面对面交流——它有表情、会点头、口型精准同步,视频生成同步对应音频,就像真人视频通话一样自然。
几个关键的亮点:
·0.33秒首帧响应,告别传统视频生成的分钟级等待
·24.82 FPS流畅输出,真正的实时交互体验
·单张GPU即可运行,从云端渲染到本地部署
·响应速度提升250倍,将Sora 2、Veo 3等模型需要1~2分钟的生成压缩到亚秒级
"多模态能动性"正在重新定义AI交互的未来。 AI与人、甚至AI与AI之间的互动,不再局限于文字、语音或视频单一模态,而是像人类一样——看得见、听得到、能表达、会回应。LiveTalk迈出了关键的一步:将视频生成从"离线渲染"推向"实时交互",让AI真正"现身说法"。
·论文链接:https://arxiv.org/abs/2512.23576
·代码链接:https://github.com/GAIR-NLP/LiveTalk
·模型链接:https://huggingface.co/GAIR/LiveTalk-1.3B-V0.1
在当前视频生成领域,主流模型仍以“离线渲染”为核心范式。以 Sora 2、Veo 3 等系统为代表,视频生成通常依赖云端算力完成,往往需要排队并经历1 ~ 2分种的渲染,难以满足实时交互、人机对话等在线场景对端到端低延迟的迫切需求。在这一背景下,LiveTalk 正式发布,首次在单卡环境下实现“强交互”的实时对话视频扩散模型,将响应速度提升至传统方案的 250 倍。LiveTalk 是一个面向实时多模态交互的视频生成系统,基于 1.3B 参数的小模型架构,从设计之初即围绕端到端时延进行系统级优化,突破了视频生成“非实时”的长期技术瓶颈。
技术层面,LiveTalk 采用块级自回归 + 少步因果扩散的架构,并对多模态蒸馏流程进行了系统性重构。在保证视频质量、人物一致性与音画同步的前提下,模型可在 0.33 秒内生成首帧,并以 24.82 FPS 的速度实现稳定的流式输出,真正达到实时视频生成标准。
应用层面,LiveTalk 可与语音和语言大模型深度协同,在对话过程中持续生成响应视频,支持分钟级人物一致性与自然的多轮人机对话体验,实现高度拟人化的实时呈现。这一能力标志着数字人视频生成正式从“单次出片”迈入“实时交互”时代,为在线对话、虚拟助手、数字人直播等场景提供了全新的技术基础。
核心贡献
1)实时生成能力:将分钟级视频生成压缩到秒级交互延迟
在保持相近画质前提下,LiveTalk 将传统 5–10 秒视频生成常见的分钟级延迟,压缩到 0.33 s 首帧响应 + 24.82 FPS 持续生成。在实际系统中,模型能够一边接收语音一边生成新帧,使播放帧率稳定接近实时渲染,从“离线出片”过渡到可用于在线交互的响应速度。
2)稳定的多模态蒸馏加速:面向多模态条件的稳定蒸馏加速方案
针对多模态场景下蒸馏过程易崩溃的问题,该工作在 Self Forcing 类在线自蒸馏框架上进行了定量地分析与实验改造:通过多模态条件精修(高质量人像、动作导向的文本提示、自然语音)、充分收敛的 ODE 蒸馏初始化,以及有效利用分布匹配蒸馏算法的有限训练窗口,使教师–学生在多模态输入条件下的分布匹配蒸馏过程显著稳定,基本消除了黑帧、严重闪烁和音画错位等失真现象,为多模态条件输入的视频蒸馏加速提供了一条可复现的工程路径。
3)支持流式交互的块级自回归模型与系统架构
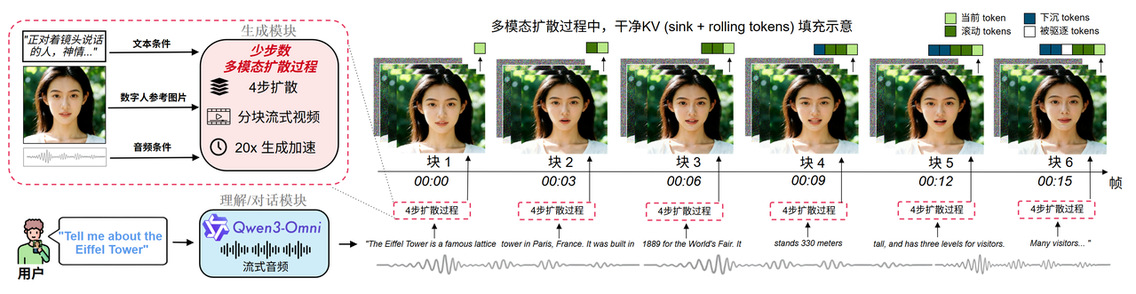
在模型层面,LiveTalk 将多步双向视频扩散压缩为 4 步因果扩散的块级自回归学生模型,在 VAE 潜空间中按块生成,并通过因果注意力与 KV Cache 在块间传递“记忆”,在保证人物与动作长时间一致性的同时显著降低单步计算量。在系统层面,LiveTalk 引入了负责理解多轮指令并生成语音回复的大模型用于交互,并将其与学生视频模型解耦。系统对流式语音做滑动窗口编码、以块为单位触发视频生成,并行执行扩散去噪与 VAE 解码,使视频生成速度持续领先于播放。并通过改进注意力下沉机制缓解长时生成中的身份漂移,从而支撑稳定的实时多轮对话交互。
4)多轮视频对话评测基准:从单轮生成扩展到持续交互
该工作还构建了一个面向多轮对话的视频生成评测基准,用于系统评估模型在真实交互过程中的表现,包括多轮视频一致性、上下文理解以及整体交互体验等维度。在这一基准上,LiveTalk 相比现有的闭源视频生成模型系统Sora2和Veo3,在多轮对话场景中展现出更好的理解能力和可用性,为实时多模态系统提供了更贴近应用侧的评测框架。
一、技术背景
从技术路线来看,当前主流视频扩散模型仍以完整序列建模 + 多步双向扩散为主。这类模型在生成质量和画面表现上已经相对成熟,但在实际部署中普遍面临三方面约束:一是时延较高,生成 5–10 秒视频往往需要 1–2 分钟,难以支撑需要即时反馈的实时交互场景;二是计算成本高,长序列、多步扩散意味着显存占用和算力开销都非常可观;三是交互能力有限,大多数系统仍主要服务于单轮“文生视频”,难以自然承载语音对话、多轮上下文等更复杂的人机交互形态。
在这样的背景下,社区开始探索通过蒸馏加速,将这类双向、多步的扩散模型压缩为更高效的因果、自回归、少步数学生模型,以在尽量保持画质的前提下降低推理时延。不过,现有工作大多仍停留在相对简单的文本生成视频场景;在引入复杂多模态条件(尤其是图像 + 音频联合驱动)时,以 Self Forcing 为代表的在线自蒸馏方法会出现明显的视觉伪影,例如闪烁、黑帧以及整体质量退化,使得多模态条件下的蒸馏难以稳定训练并应用于实时系统。
围绕这一系列限制,LiveTalk 所聚焦的核心问题可以概括为:在复杂多模态条件输入的情况下,如何稳定地将视频扩散模型蒸馏为可实时推理的模型,并在此基础上构建完整的实时多轮对话交互系统。
二、方法:面向多模态视频的在线自蒸馏框架
在上述背景下,LiveTalk 基于在线蒸馏代表方法 Self Forcing 的基础上,面向多模态视频提出了一套改进的在线自蒸馏框架。整体流程分为两阶段:先通过ODE 蒸馏初始化将教师模型的多步扩散过程压缩为学生模型的4 步因果扩散;再在此基础上,通过分布匹配蒸馏(DMD算法在自回归采样轨迹上对齐教师与学生,以缓解长序列生成中的 exposure bias 和分布偏移。
围绕这一框架,LiveTalk 结合实证分析,针对多模态条件下 Self Forcing 训练易出现闪烁、黑帧和质量退化等问题,提出三项关键改进。
01多模态条件精修

首先,在“多模态条件本身质量不足会放大训练不稳定性”这一点上,LiveTalk 对蒸馏时使用的多模态条件进行了显式精修与筛选:
·样本筛选与质量过滤:在 Hallo3、HDTF 等数据集上,从参考图像 + 音频对中选取子集,并基于亮度、清晰度等指标过滤掉质量较差的样本,以减少极端条件对 DMD 训练的干扰;
·图像增强:针对数据集中人脸模糊的问题,一方面对参考头像图像引入超分辨率处理,另一方面在部分样本上通过 Qwen-Image 重新生成语义相近的人像,以获得更清晰、稳定的人脸细节,便于模型学习稳健的身份与外观表示;
·文本提示重写:利用 Qwen2.5-VL-72B 对文本 prompt 进行重写,使条件文本更加“动作/表情导向”,强调动态运动和面部表情等时间相关信息,而不仅是静态外观描述。
这一系列操作的目标,是在不改动主干网络的前提下,通过提升条件输入本身的信噪比来减轻不稳定性,为后续 ODE 与 DMD 阶段提供更可靠的多模态驱动信号。
02充分收敛的 ODE 蒸馏初始化
其次,论文的分析表明:在多模态设定下,如果 ODE 初始化阶段训练不足,学生模型在部分时间步上的去噪能力会明显偏弱,随后在分布匹配蒸馏阶段就容易出现两类失败模式——严重时直接崩溃(黑屏、模式崩塌),较轻时则表现为长时间的模糊与质量停滞。
为此,LiveTalk 相比原始 Self Forcing 显著延长了ODE初始化的训练日程,将其训练至充分收敛:
·采用扩展的训练步数,使学生模型在全时序上都学会稳定去噪;
·以“收敛的 ODE checkpoint”作为 DMD 的起点,为后续 critic–generator 交替优化提供一个相对稳固的基线。
实验结果也印证了论文中的结论:在多模态场景下,充分收敛的 ODE 初始化被证明是 DMD 稳定收敛的重要前提之一,对后续训练过程的稳定性有显著影响。
03有限窗口内的强化分布匹配策略
最后,作者观察到:多模态条件下的在线自蒸馏存在一个相对有限的“有效学习窗口”——在训练前几百步内,性能指标提升明显,而继续训练则容易进入质量退化甚至崩溃阶段。因此,LiveTalk 的策略不是一味拉长 DMD,而是在这段有限窗口内尽可能提升每一步的有效学习量:
·采用更“激进”的学习率配置,对生成器和判别器整体放大学习率,以加快早期收敛;
·在教师分数网络上调高 CFG 系数,加强教师对音画同步等关键属性的约束,从而在 Sync-C、Sync-D 等指标上获得可观收益。
结合多模态条件精修、收敛的 ODE 初始化以及这一“有限窗口内强化学习”的 DMD 配置,LiveTalk 在实验证明可以显著减少闪烁、黑帧和整体质量退化等现象,使多模态视频蒸馏在工程上变得可稳定复现、可直接用于后续实时系统。
三、模型与系统:从因果视频生成模型到实时对话系统
在模型层面,LiveTalk 以双向视频扩散的数字人生成模型 OmniAvatar 为教师模型,通过前文所述的 ODE 初始化与分布匹配蒸馏,得到一个 1.3B 参数规模的因果学生模型。该学生模型在因果注意力机制下采用 4 步扩散完成去噪,高效生成当前视频块。具体而言,LiveTalk 通过块级自回归的方式沿时间轴逐块生成视频,并在相邻块之间填充来自前序块的 KV 缓存,用于维持长时间尺度上的人物外观、表情与动作连续性。在这一设计下,模型一方面继承了扩散模型在视觉质量上的优势,另一方面具备了自回归结构的流式生成能力,并且可以在每个块生成时同步更新与调整当前输入的多模态条件,从而为后续的实时系统提供一个可扩展的、低延迟的视频生成内核。
在系统层面,作者在该模型之上构建了完整的实时多模态交互系统 LiveTalk。系统引入 Qwen3-Omni 作为负责理解与对话的大模型模块,用于接收用户的语音或文本输入,进行多轮推理并生成流式语音回复;由 Qwen3-Omni 输出的连续音频,再与参考人像图像以及描述动作与表情的文本提示共同作为条件输入到 LiveTalk 的视频扩散模型中。视频侧以这些多模态条件为驱动,以块级自回归的方式逐步生成与语音同步的说话人视频:一方面通过滑动窗口对流式音频进行编码,获取足够的声学上下文以支撑自然的口型与肢体运动。相比接受完整音频输入而言,降低了系统层面的端到端延迟;另一方面在扩散去噪与 VAE 解码之间采用流水线并行,使当前块去噪的同时,上一块已经完成解码和播放。此外,作者提出无需训练的"身份锚点主导的注意力汇聚槽"技术(Anchor-Heavy Identity Sinks), 以缓解长时生成中的身份漂移:在 KV cache 内以更高比例固定保留早期高保真说话人帧作为“身份锚点”,仅保留少量滚动 KV 承载语义上下文。该设计出发点是在同等 KV 预算下将注意力更多汇聚到稳定身份表征、减少对后续误差块的关注,从而在数分钟视频生成中保持外观一致性。得益于块级生成、KV 预填充以及音频对齐等设计,整个系统在实际交互中能够始终保持生成速度领先于播放速度,从而实现接近在线通话体验的实时多轮对话。
四、实验与评测
在单轮生成场景中,作者基于蒸馏后的1.3B 因果学生模型与 AniPortrait、Hallo3、FantasyTalking 以及双向教师 OmniAvatar-1.3B/14B 进行对比。评测在 HDTF 测试集(域内)以及 AVSpeech、CelebV-HQ(跨域)上展开,使用标准的画质、美学与音画同步指标,并在 512×512 分辨率下测量吞吐率和首帧时延。结果表明,LiveTalk 在视觉质量与唇形同步上与同规模的双向多步教师相当,部分指标接近甚至超过更大规模模型;与此同时,推理效率提升显著:吞吐率达到 24.82 FPS(对比 0.97 FPS),首帧时延从 83.44 s 降至 0.33 s,在时延和吞吐上分别获得约两到三个数量级的加速,为实时应用预留出充足的性能空间。
、美观度(ASE) 以及唇形同步(Sync-C,Sync-D) 性能方面与双向教师基线 OmniAvatar-1.3B 相当,甚至更优,同时实现了约 20× 的吞吐率提升和约 200× 更快的首帧延迟。") 在测试集上与现有多模态虚拟形象生成方法进行定量比较。我们的蒸馏模型在视觉质量 (FID、FVD、IQA)、美观度(ASE) 以及唇形同步(Sync-C,Sync-D) 性能方面与双向教师基线 OmniAvatar-1.3B 相当,甚至更优,同时实现了约 20× 的吞吐率提升和约 200× 更快的首帧延迟。
在测试集上与现有多模态虚拟形象生成方法进行定量比较。我们的蒸馏模型在视觉质量 (FID、FVD、IQA)、美观度(ASE) 以及唇形同步(Sync-C,Sync-D) 性能方面与双向教师基线 OmniAvatar-1.3B 相当,甚至更优,同时实现了约 20× 的吞吐率提升和约 200× 更快的首帧延迟。
为了反映真实对话中的表现,论文进一步提出多轮交互评测:模拟用户与系统进行对话,由大规模视觉语言模型从多视频一致性、内容质量、交互自然度等 9 个维度打分,并对所有模型的得分进行统一池化和 z-score 标准化后转成百分位数,便于横向比较。对比 Veo3 和 Sora2,LiveTalk在多轮一致性和整体内容质量等与“对话体验”直接相关的维度上整体占优,同时保持竞争性的视觉效果和音画同步;在交互实时性维度上,LiveTalk 在 1 秒级时延下即可完成单轮视频交互,而 Veo3、Sora2 单轮生成仍需数十秒,难以维持连贯对话,这凸显了前者在实时多模态场景中的优势。
,NI:非语言互动(Nonverbal Interaction),MVC:跨轮交互视频连贯性(Multi-Video Coherence),CN:对话自然度(Conversational Naturalness); SR:语义相关性(Semantic Relevance),IC:信息完整性(Information Completeness),LC:逻辑一致性(Logical Consistency),CU:上下文理解(Context Understanding),OIE:整体交互体验(Overall Interaction Experience)。") 多轮交互质量评估。我们在所提出的交互基准上,将本方法与各基线方法进行对比评测。我们报告交互视觉质量与交互内容质量两类指标的 Z-Score 百分位数结果,并同时给出平均推理吞吐率以及每轮交互的平均延迟。加粗表示最佳性能,下划线表示次优。 EA:情感得体性(Emotional Appropriateness),NI:非语言互动(Nonverbal Interaction),MVC:跨轮交互视频连贯性(Multi-Video Coherence),CN:对话自然度(Conversational Naturalness); SR:语义相关性(Semantic Relevance),IC:信息完整性(Information Completeness),LC:逻辑一致性(Logical Consistency),CU:上下文理解(Context Understanding),OIE:整体交互体验(Overall Interaction Experience)。
多轮交互质量评估。我们在所提出的交互基准上,将本方法与各基线方法进行对比评测。我们报告交互视觉质量与交互内容质量两类指标的 Z-Score 百分位数结果,并同时给出平均推理吞吐率以及每轮交互的平均延迟。加粗表示最佳性能,下划线表示次优。 EA:情感得体性(Emotional Appropriateness),NI:非语言互动(Nonverbal Interaction),MVC:跨轮交互视频连贯性(Multi-Video Coherence),CN:对话自然度(Conversational Naturalness); SR:语义相关性(Semantic Relevance),IC:信息完整性(Information Completeness),LC:逻辑一致性(Logical Consistency),CU:上下文理解(Context Understanding),OIE:整体交互体验(Overall Interaction Experience)。
此外,作者对提出的在线自蒸馏改进方法进行了消融,包括多模态条件精修、延长 ODE 初始化至收敛、在有限 DMD 窗口内采用更激进的学习率,以及提高教师 CFG 系数等。实验显示,直接沿用原始 Self Forcing 配置时,蒸馏视频质量明显退化;逐步加入上述改动后,黑帧、闪烁等伪影被依次消除,各项质量与音画同步指标稳步提升,最终形成一套在多模态条件下可稳定复现、并能支撑实时系统的蒸馏方案。
 消融实验展示了各项改进带来的影响。表中每一行依次加入一个组件。“最终配置”表示在应用所有改进后性能最优的配置。最后一行表示在应用其余所有改进的情况下,采用基线的多模态条件设置。
消融实验展示了各项改进带来的影响。表中每一行依次加入一个组件。“最终配置”表示在应用所有改进后性能最优的配置。最后一行表示在应用其余所有改进的情况下,采用基线的多模态条件设置。
五、应用前景
目前,LiveTalk 已在 GitHub 开源代码,并在 Hugging Face 提供 LiveTalk-1.3B-V0.1 模型权重,采用 Apache 2.0 许可证,便于科研和工业界在此基础上进行二次开发与部署。
结合其实时性与多模态能力,LiveTalk 的相关技术路线在多个场景中具备直接落地的潜力,例如:面向客服与企业服务的实时数字人与虚拟助理,可支持多轮问答、情绪表达与品牌化形象;在线教育与培训场景中,以讲解人视频的形式同步呈现课程内容与互动答疑;面向内容创作和直播增强,为主播或创作者提供低成本、可定制的虚拟形象;以及作为多模态智能体的可视化前端,将语言规划与视频生成有机结合,提供更自然的人机交互界面。
从研究视角来看,LiveTalk 提供了一条经过实证验证的技术路径:在保持生成质量的前提下,将大规模双向视频扩散模型可靠地蒸馏为小规模因果自回归模型,并在复杂多模态条件下兼顾训练稳定性与推理实时性。更长远地看,这类“可实时对话的视频生成系统”有望成为下一代人机交互范式的基础组件——未来用户与模型的互动,不再是抽象的文本或语音指令,而是与具备持续记忆、稳定身份和自然表达能力的“数字角色”进行面对面交流。LiveTalk 所探索的,是从单次内容生成迈向长期在线交互的一条可能路径,也为构建具身智能体、数字社会基础设施等更宏观的愿景打下了关键一环。
