
一、引言
视觉-语言-动作(VLA)模型在各个评测基准中频频刷出高分,这些亮眼成绩背后,是否隐藏着严重的泛化缺陷?
在固定相机角度、稳定光照条件下训练表现优异的模型,在面对视角轻微偏移、机器人初始姿态微小变化时能否真正有效泛化?
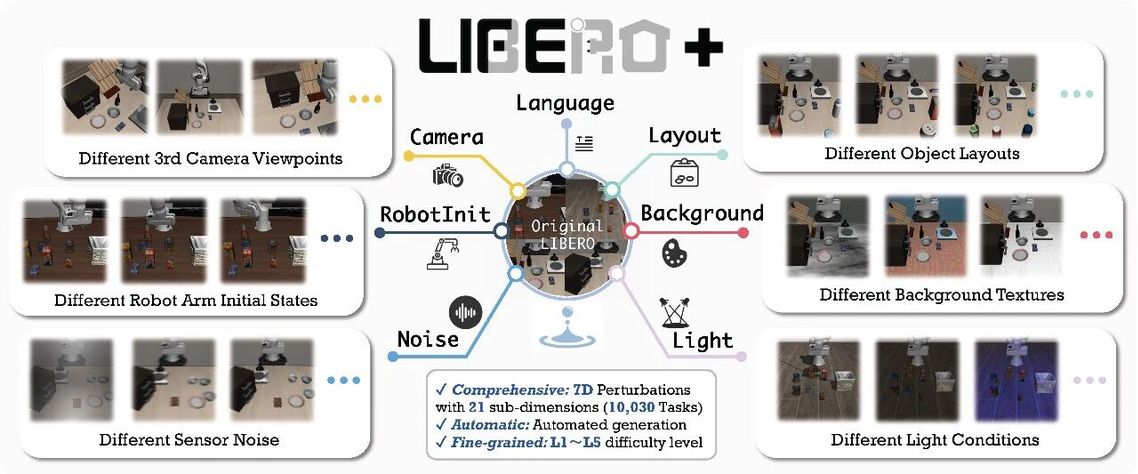
上海创智学院 OpenMOSS 团队发布了 LIBERO-Plus,首次对主流 VLA 模型进行了系统性、全方面、细粒度的鲁棒性分析,覆盖7大扰动维度、21项子类、5个难度等级,揭示了表面高分数之下存在的鲁棒性赤字。看完这篇工作,你会发现“ 高分数 ≠ 真智能 ”。
论文标题:LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models 论文链接:https://arxiv.org/pdf/2510.13626 项目主页:https://sii-research.github.io/LIBERO-plus/ 代码仓库:https://github.com/sii-research/LIBERO-plus 作者单位:创智,复旦,同济,新国立
二、动机和贡献
近年来,VLA 模型在 LIBERO 等机器人操作基准测试中取得了令人瞩目的成绩,多个工作实现了接近完美的成功率。然而,当前主流的评估方法主要关注静态理想条件下的总体成功率,它们无法评估策略在真实变化下的稳定性和可靠性,这些高分模型是否真正具备多模态理解能力,还是仅仅过拟合于理想训练环境?
为探究上述问题,我们提出了 LIBERO-Plus,从 (i) 物体摆放, (ii) 相机视角, (iii) 机器人初始姿态, (iv) 语言指令, (v) 光照条件, (vi) 背景贴图, (vii) 传感器噪声 七个维度,对模型进行泛化性能测试。贡献如下:
(1)通过系统性的添加扰动,对当前 VLA 模型进行了详尽的泛化性分析。
(2)提出一个分析基准,用于识别和量化各类扰动对模型性能的影响。
(3)针对模型表面性能与实际泛化能力之间的失配问题,提供了关键性洞见。

 改变相机视角及初始位姿时的典型失败案例
改变相机视角及初始位姿时的典型失败案例
代码、数据、模型全开源,只需 3 步即可从 LIBERO 迁移到 LIBERO-Plus!
代码数据模型
代码仓库:https://github.com/sii-research/LIBERO-plus 资产地址:https://huggingface.co/datasets/sii-research/LIBERO_plus_assets/tree/main rlds 数据:https://huggingface.co/datasets/sii-research/libero_plus_rlds/tree/main lerobot 数据:https://huggingface.co/datasets/sii-research/libero_plus_lerobot/tree/main 模型权重:https://huggingface.co/sii-research/openvla-7b-oft-finetuned-libero-plus/tree/main 快速迁移
step1:拉取仓库、下载资产 step2:安装 LIBERO-Plus step3:安装新增依赖
git clone https://github.com/sii-research/LIBERO-plus.git
cd LIBERO-plus && pip install -e .
pip install -r extra_requirements.txt三、单维度扰动如何影响 VLA 模型?
下表汇总了各模型在不同维度扰动下的性能表现:每个模型的首行数据为各扰动维度下的任务成功率(%),Original 列表示无扰动时的原始性能,次行(以↓标示)则展示相应的绝对性能下降值。

由此发现:
(1)模型对扰动存在显著的整体脆弱性,模型在各维度扰动下性能均有所下降; (2)鲁棒性表现随扰动类型差异显著,对相机视角与机器人初始状态的变化最为敏感(这两类扰动需具备高层次空间几何与本体感知理解),而对光照与背景变化则相对鲁棒(此类扰动属于更表层的低阶视觉变化); (3)语言扰动对模型性能影响较小,这种表面鲁棒性有违直觉,需深入探究; (4)模型鲁棒性受架构与训练范式主导,融合第一人称腕部摄像头、强调数据多样性、协同训练的模型展现出更优的泛化能力。
四、VLA 模型是否真正遵循语言指令?
语言扰动在大多数模型中引发的平均性能下降幅度最小(-25.3%)。这种表面上的鲁棒性有违直觉,值得深入探究。

(a) 空白指令测试:只给模型输入空字符串指令
令人惊讶的是,即使在没有有效语言输入的情况下,部分模型的性能仍基本保持不变。实际上,这些模型退化为忽略语言模态的架构,其行为模式更接近视觉-动作(VA)模型。(b) 目标替换测试:将要移动或操作的目标对象替换为另一物体
当语言指令中的目标对象被替换为其他物体时,模型仍持续执行原始任务,导致修改场景中的成功率骤降。

 当改变任务语言指令,模型仍然在执行相同的轨迹
当改变任务语言指令,模型仍然在执行相同的轨迹
VLA 模型不具备跨对象指令跟随的强泛化能力。在任务决策过程中,它们更倾向于依赖固定的视觉-动作映射机制,而非充分挖掘语言信号的价值。
五、VLA 模型是否真正关注视觉输入?
模型对背景变化展现出惊人的适应能力,且对光照变化的敏感性有限。这一现象激发了我们进一步的探索:模型究竟在学习何种表征?
模型是否真正关注任务相关物体?
我们将“物体布局扰动”分解为两个子类别:(1)添加干扰物体(confounding);(2)改变目标物体的位置和姿态(Displacement)。随后,我们在这两种条件下对所有模型进行了评估,结果见下图。

实验表明,模型虽能有效忽略干扰物,却在目标物体位置变化时出现泛化失败。这表明其依赖记忆中的位置线索,而非真正学习到具有不变性的物体语义特征。
模型如何在光照变化下保持鲁棒?
我们设计了一个极端消融实验:(1)全黑场景(all-black):所有相机输入均替换为黑帧;(2)第三人称视角黑帧(3rd-black):仅屏蔽第三人称视角,保留腕部相机视角。

试验表明,模型在光照扰动下性能衰减有限,主要因为光照变化会影响第三人称视角的全局外观,而腕部视角保持相对稳定,能持续提供关键的近距离几何空间信息。
六、多维度扰动下是否存在组合泛化差距?
单维度扰动下的泛化结果反映了模型对孤立因素的鲁棒性,但这些维度之间可能并非相互独立,不同类型的扰动可能存在复杂的依赖关系。我们将模型在多维度扰动下的性能称为“组合泛化能力”,并从统计学角度对这一问题进行定义。同时提出"组合泛化差距"的概念,定义为成功条件下扰动变量间的协方差:
用以量化模型在组合扰动下的性能表现,其中:
:施加扰动的指示变量,1代表存在扰动,0代表不存在 :任务成功的指示变量 ,1代表成功,0代表失败 表示扰动间存在负向交互效应,超出了两个单一扰动的独立影响

上图展示了成对扰动下的条件概率热力图。上三角区域表示基于独立性的单维度概率乘积,下三角区域则呈现实际的联合作用结果。
实验结果显示持续存在的负向组合差距,表明当前 VLA 模型缺乏组合泛化能力。其学习到的表征存在纠缠现象,无法有效处理现实环境中特有的复杂多维度扰动。
七、LIBERO-Plus 评测基准
基于上述分析,我们构建了包含 10,030 个任务的评测基准 LIBERO-Plus,基于扰动增强策略构建了大规模的训练集,并在 OpenVLA-OFT 基础上进行混合微调。
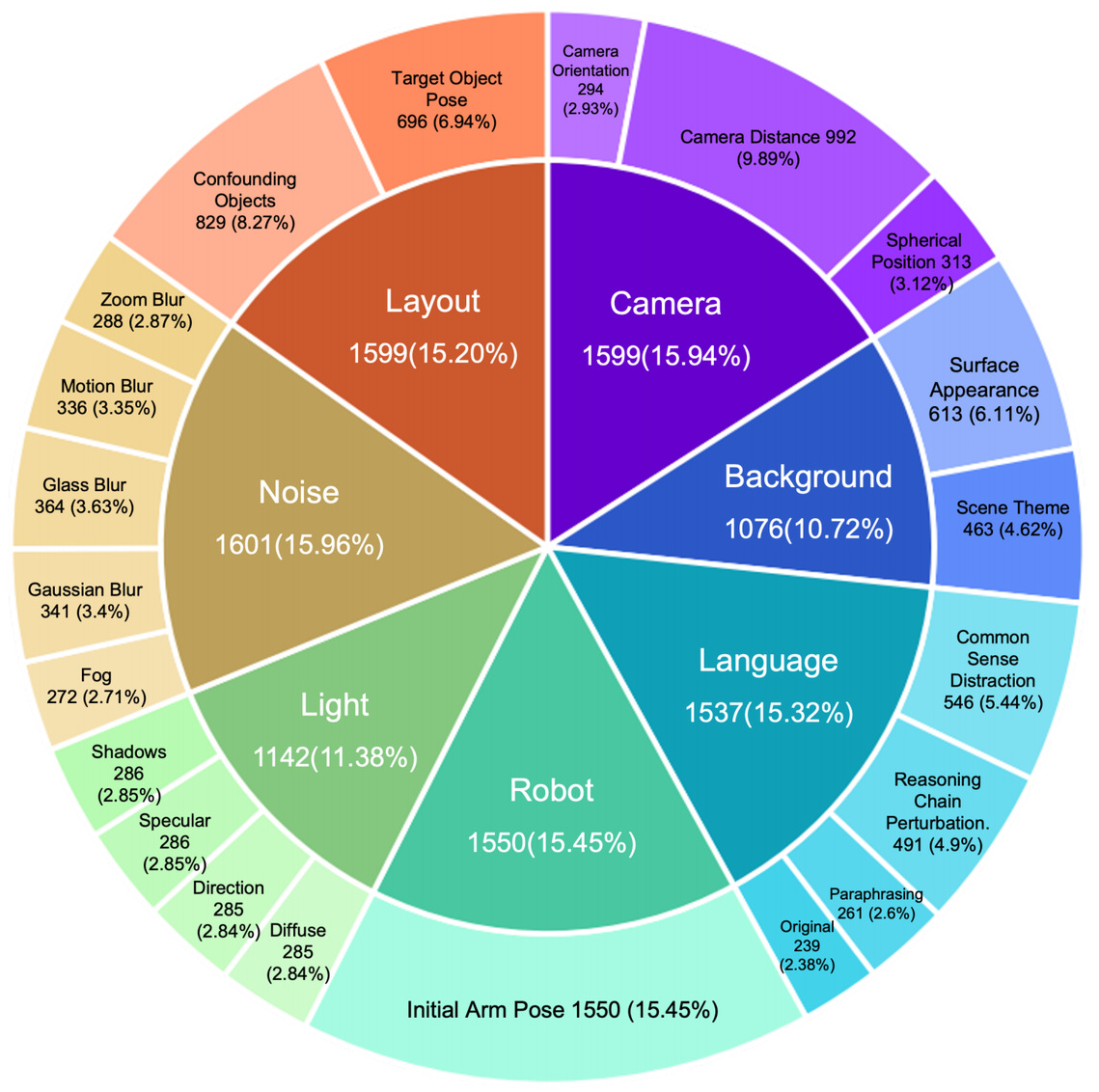
本基准具备以下特点:
全面性:覆盖7大扰动维度、21项子类; 自动化:使用自动化方法大规模生成; 细粒度:L1~L5 五个难度等级。

数据泛化是否能带来性能泛化?
利用我们造出来的数据集,我们对 OpenVLA-OFT 的官方模型进行了混合数据微调,在 LIBERO-Plus 基准测试上的相应结果如下表所示。
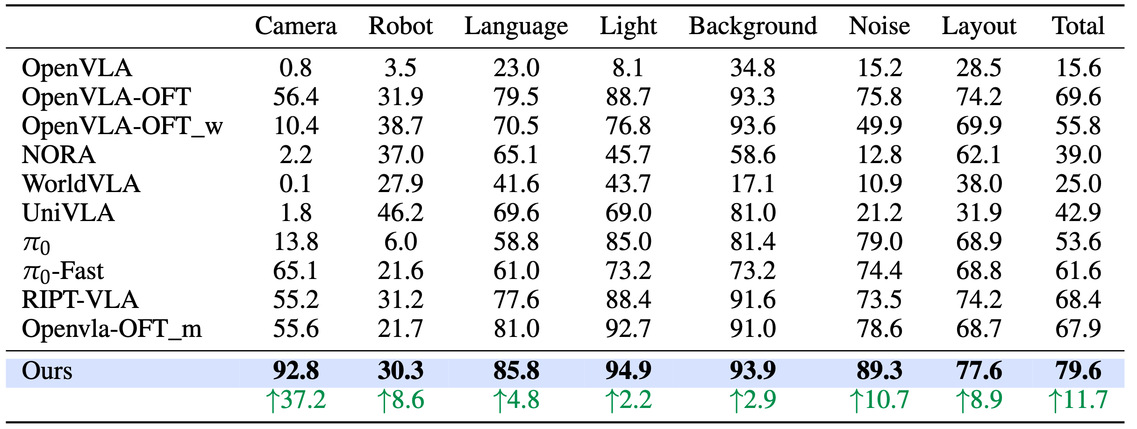
实验表明:在 LIBERO-Plus 上,采用增强数据训练的模型取得了 79.6% 的平均成功率,显著优于基线,在相机视角扰动上提升了 37.2%。
八、One More Thing
除了系统的鲁棒性分析,我们还为大家准备了一份 “一站式”性能追踪利器——实时更新的双榜单系统!
LIBERO-Plus 鲁棒性排行榜
全面评估模型在七大扰动维度下的表现:
👉 直达链接:https://github.com/sii-research/LIBERO-plus?tab=readme-ov-file#-libero-plus-benchmark-leaderboard
原始 LIBERO 性能榜
同步追踪模型在原始任务上的基础表现:
👉 直达链接:https://github.com/sii-research/LIBERO-plus/blob/main/libero_res.md#-model-performance-comparison-on-libero-benchmark
诚邀社区伙伴一同参与!如果你也在探索VLA模型的边界,欢迎测试你的模型并提交 PR,共同丰富这份不断进化的性能图谱!
九、结语
LIBERO-Plus 首次系统性、细粒度地揭示了当前 VLA 模型在视觉理解、语言交互、组合泛化等方面的鲁棒性缺陷。
研究发现,当前大多数 VLA 模型在泛化时仍显脆弱,尤其对相机视角与初始位姿变化表现出高度敏感性;一些模型几乎忽视了语言指令;部分模型仅依赖轨迹记忆而非视觉反馈执行任务;组合扰动会对模型能力产生负向干扰。我们呼吁社区不应再盲目追求“刷榜”,而应关注模型在真实多变环境下的稳定性,推动 VLA 从“看起来聪明”走向“真正可靠”。
