
马克思说:“人的本质是社会关系的总和。”
我们说:“人是所有上下文的总和。”
这一切的起点,是一个被严重误解的领域——Context Engineering(上下文工程)。上海创智学院刘鹏飞老师团队最新发布的报告《上下文工程 2.0》,剖析上下文工程的:本质、历史与未来。不仅打破了"上下文工程是大语言模型时代新发明"的误解,将这一实践追溯到20多年前的普适计算和人机交互领域,更表示:在AI时代,人不再仅由肉体和意识定义,而是由其产生和嵌入的所有上下文定义。当员工离职后,他的数字上下文——邮件、决策模式、工作流程——仍在AI系统中延续。
一个被遗忘的30年历史
2000年,Dey团队开发了Context Toolkit——一个帮助开发者构建“上下文感知应用”的框架。当你走进办公室,系统会自动:检测你的位置(通过红外传感器)、识别你的身份(通过ID卡)、推断你的活动(会议 vs 个人工作)、调整环境(灯光、温度、通知模式)。
这个过程需要什么?需要工程师精心设计传感器网络、数据融合算法、推理规则——将高熵的原始信号(位置坐标、时间戳、环境数据)转化为机器可以理解的低熵表示(“用户正在开会,不要打扰”)。
这就是Context Engineering的雏形。
再往前推,1994年,Bill Schilit在他的博士论文中首次提出“context-aware computing”(情境感知计算)的概念。2001年,Dey给出了至今仍被广泛引用的定义:
"Context is any information that can be used to characterize the situation of an entity."
(上下文是任何可以用来刻画实体情境的信息)
“所以,当我们说‘上下文工程已经30岁了’,这不是夸张,而是事实,”团队负责人刘鹏飞强调,“上下文工程火了之后,所有人都以为这是大模型时代带来的新概念。但实际上,上下文工程的思想可以追溯到1991年Mark Weiser提出的‘普适计算’愿景——那时的研究者就在思考:如何让机器理解'用户在哪里、在做什么、需要什么'。”
论文系统梳理了上下文工程的三次进化:
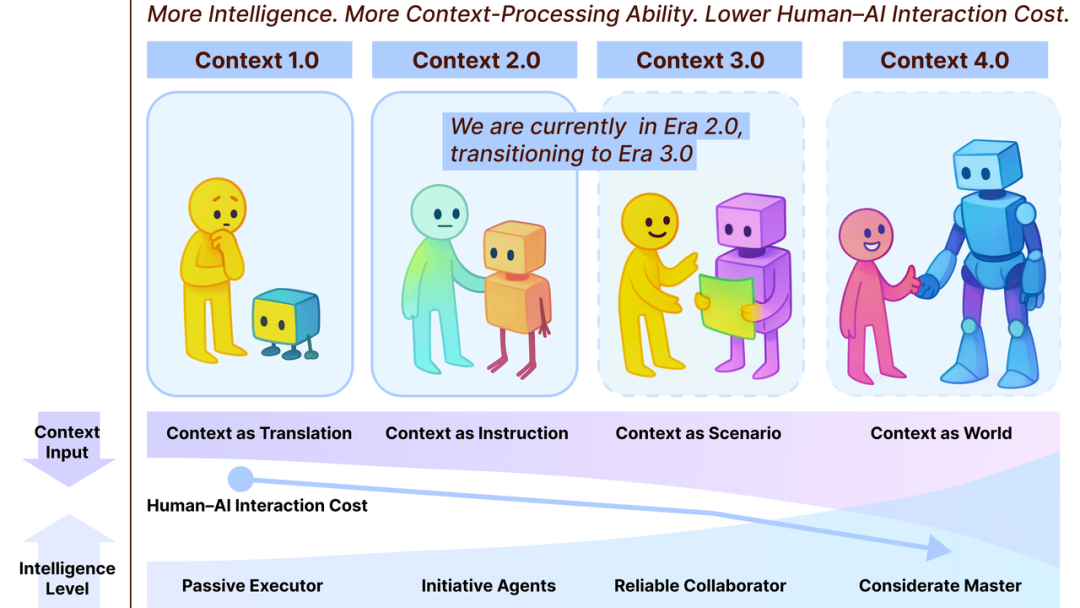
1.0时代(1991-2010):研究者用传感器自动收集位置、时间、环境等物理上下文,通过规则和推理引擎让机器"感知"用户情境。
1.5时代(2010-2022):移动互联网和API让数字上下文(日历、联系人、历史记录、社交网络)成为可能,机器开始理解你的数字生活。
2.0时代(2022至今):大语言模型让我们可以用自然语言直接构建复杂的任务上下文,机器第一次能够理解你用人类语言表达的意图和背景。
3.0时代(未来):类人智能阶段,机器有望实现接近人类的理解与推理能力,能够吸收高熵、多模态、社会与情绪信号等丰富上下文,实现自然协同,成为真正有知识与判断力的“同伴”。
4.0时代(推测):超人智能阶段,机器理解与塑造上下文的能力超越人类,开始主动引导人类思考,构造新的语境与需求。人机关系发生倒挂,AI 成为洞察与创新的源泉。
“Context Engineering不是新发明,它是一个持续30年的进化过程。变化的是:机器能理解的‘你’越来越完整;不变的是:人类一直在努力让机器理解‘什么是人’。”
第一性原理:为什么机器需要上下文?
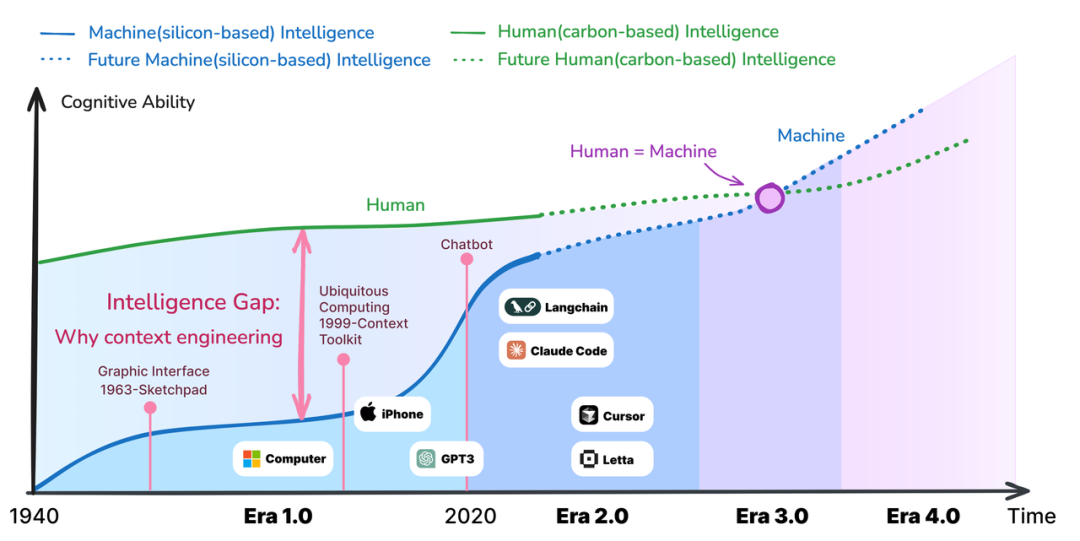
论文最精妙之处在于揭示了上下文工程产生的第一性原理:人与机器之间存在巨大的认知智能鸿沟(Cognitive Intelligence Gap)。
“人类是天生的‘脑补’大师,”论文解释道,“当你说‘帮我订明天的会议室’,人类同事会自动推断:哪个办公楼、几点到几点、需要投影仪吗、要邀请谁。这些信息在你的大脑中以‘高熵’状态存在——模糊、隐含、依赖常识。但机器无法‘脑补’,它需要将这些高熵信息降解为低熵的、明确的、结构化的指令。”
论文将上下文工程定义为一个“熵减少过程”:从人类的模糊意图,到机器可执行的精确指令。这个视角优雅地统一了30年来所有形式的人机交互——从2000年Context Toolkit的传感器数据预处理,到今天的Few-shot Prompting,本质上都在做同一件事:减少不确定性,填补认知鸿沟。
每一次技术跃升,都重写一次交互界面

论文发现了一个被忽视的规律:每当机器智能提升一个台阶,就会催生一次交互界面革命。
上世纪80年代,当计算机从只能理解机器码进化到理解命令行,CLI(命令行界面)诞生;当它能理解图形和鼠标点击,GUI(图形界面)取代了CLI;当智能手机让机器能理解触摸和手势,移动互联网爆发;当大语言模型让机器能理解自然语言,Chat界面开始颠覆一切。
“这不是偶然,”团队负责人指出,"每一次机器能力边界扩展,都会让旧的交互范式变得低效。就像你不会用命令行去刷抖音,未来你也不会用传统APP去做复杂的多步骤任务。缩小的认知鸿沟,呼唤着新的交互容器。”
这意味着巨大的产业机会:从PC电脑到微信,每一次交互界面(interface)革命都诞生了万亿级市场。论文预言,随着大模型能力迅速逼近人类水平,下一个微信级产品,一定藏在这个新的认知鸿沟中。
认知反转:
当AI超越人类,上下文工程会消失吗?
论文最具争议的部分是对"超智能时刻"的预测。当AI的认知能力接近甚至超越普通人时,会发生什么?
“一个反直觉的结论是:上下文工程不会消失,而是会发生‘认知反转’,”论文写道,“原本是人教机器理解上下文,未来可能是机器主动构建、管理、甚至创造上下文。它会比你更懂你的工作流程,主动推断你的需求,甚至质疑你的决策。”
这将我们带回开头的哲学追问:当你的数字上下文比肉体更长寿,“你”是什么?
想象一个场景:员工离职了,但他过去5年的工作上下文——邮件、会议记录、代码提交、决策模式——仍然完整保存在AI系统中。公司可以继续“咨询”这个数字化的认知副本。那么,这个人的“价值”和“存在”,是否已经从物理可用性转变为上下文可用性?
这不是科幻,而是正在发生的认识论转变。就像忒修斯之船的每块木板都被替换后,我们仍认为它是“同一艘船”,因为它保持了结构和功能的连续性——人的本质,也许不在于不断更新的肉体细胞,而在于持续积累的上下文网络。
马克思定义人的本质是“社会关系的总和”,在AI时代,这些社会关系、知识、判断力、决策模式,都可以被编码为上下文,在数字空间中延续。人本质上是所有上下文的总和。
一个统一的形式化框架
除了哲学思辨,论文还给出了工程实践者迫切需要的东西:第一个统一的上下文工程形式化定义。
论文将上下文工程拆解为四个核心环节:采集(Collect)——从多模态信号中提取原始上下文;构建(Construct)——将碎片化信息组织为结构化表示;使用(Use)——在任务执行时动态注入相关上下文;管理(Manage)——在隐私、成本、时效性之间权衡。
“这个框架统一了过去30年所有的最佳实践,”负责人介绍,“无论你在做智能家居、推荐系统,还是AI 智能体,都可以用这四个步骤审视自己的系统设计。”
“我们希望这篇论文能让上下文工程成为一个正式的研究学科,”团队负责人说,“它不应该只是Prompt工程师的雕虫小技,而应该像数据库理论、网络协议一样,有自己的第一性原理、设计模式和评估标准。”
毕竟,如果人本质上是所有上下文的总和,那么研究如何构建、表示、使用这些上下文,就是在研究人本身。
当你在ChatGPT中输入你的第一个Prompt时,你不仅在使用一个工具,你也在定义自己——通过你选择分享的上下文,通过你构建的意图表达,通过你与机器的每一次对话。
古希腊哲学家问:“忒修斯之船” —— 如果一艘船的每块木板都被替换,它还是原来的船吗?
2025年,我们问:“数字化的你” —— 如果你的所有上下文都被保存,这些上下文的总和,是你吗?
论文标题:Context Engineering 2.0: The Context of Context Engineering
论文地址:https://arxiv.org/pdf/2510.26493
Github 地址:https://github.com/GAIR-NLP/Context-Engineering-2.0
SII Personal Context:https://context.opensii.ai/
