
大模型竟把“9.11”和“9.8”理解为书籍章节编号?邱锡鹏教授团队推出的全新可解释框架,首次穿透Transformer复杂计算图景,揭示AI犯错的真实逻辑,更可对模型思维过程进行干预。
在人工智能日益深入生产与生活关键环节的今天,大模型如何“思考”、为何出错,已成为摆在科学家与产业界面前的紧迫命题。7月24日,由创智学院邱锡鹏教授领衔的OpenMOSS团队发布了一项突破性技术——全球首个规模化全流程机理可解释框架,首次实现对大模型内部逻辑的全面解析与干预。
01 错误背后,隐藏AI认知重大缺陷
近期,一个看似幼稚的错误引起广泛关注:多个主流大模型一致认为“9.11比9.8更大”。尽管可通过后续推理步骤修正,但错误根源迟迟未能揭示。

这并非简单的数值比较失误,而暴露了模型表征和概念编码的根本性缺陷。“在AI全面进入人类生活之前,提前发现其内部机制缺陷,对人机共生协作具有重要意义。”
全球顶尖AI机构,如Anthropic、OpenAI等,早已布局可解释性研究,但长期以来,Transformer模型内部状态高度压缩、概念叠加的特性,使其逻辑难以拆解。
02 利用稀疏化解耦Transformer的黑箱计算
为什么理解大模型如此困难?
以Transformer架构为例,模型内部知识被分布式存储与高度压缩,每一个隐藏状态都是多种概念的非线性叠加 (Superposition)。注意力机制虽提供了一定可视化能力,但依然无法对应到人类可理解的概念。
为解决这一难题,团队聚集了一批对可解释性有强烈兴趣的学生,开展密集技术攻关。他们提出了一种稀疏替代模型方法,成功将模型内部每一个状态映射到现实世界的具体概念。
“我们可以从复杂的计算图中抽取出模型最核心的逻辑”,邱锡鹏解释道。团队发现,模型之所以认为“9.11>9.8”,是因为将其误解为“第9章第11节”与“第9章第8节”,基于章节编号逻辑得出错误结论。
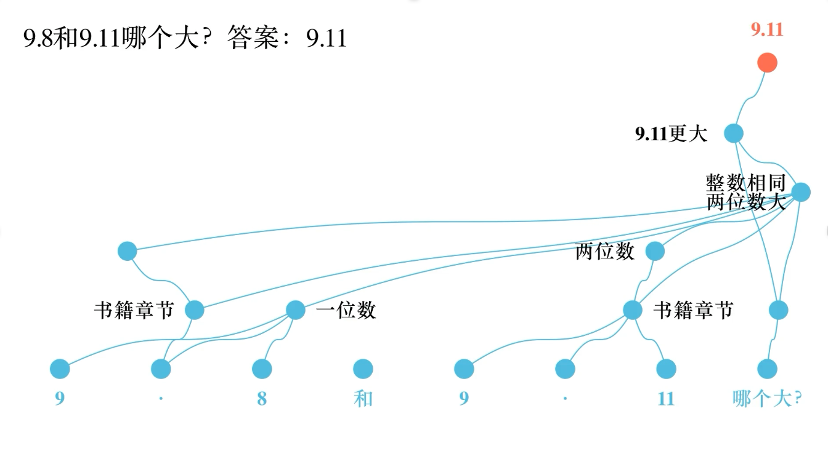
03 Lorsa:揭开AI“注意力”背后的思维单元
当我们使用大模型(如ChatGPT)时,常常会惊叹于它流畅的回答能力,但也难免困惑:它到底是如何“思考”的?为什么有时会犯一些令人啼笑皆非的错误?传统的Transformer模型就像一个黑箱,尤其是其核心组件——多头自注意力机制,长期以来难以被透彻理解。
尽管Anthropic的可解释性团队在理解模型的“神经元”(即MLP层)方面取得了突破,但注意力层的稀疏化解释一直是一个未被攻克的难题。注意力机制负责在不同词汇之间建立联系,是模型实现逻辑推理、语境理解的关键,但其内部的计算往往是多个“注意力单元”叠加在一起的结果,这种现象被称为“注意力叠加”(Attention Superposition),使得我们难以分离出每一个独立的、可解释的注意力行为。
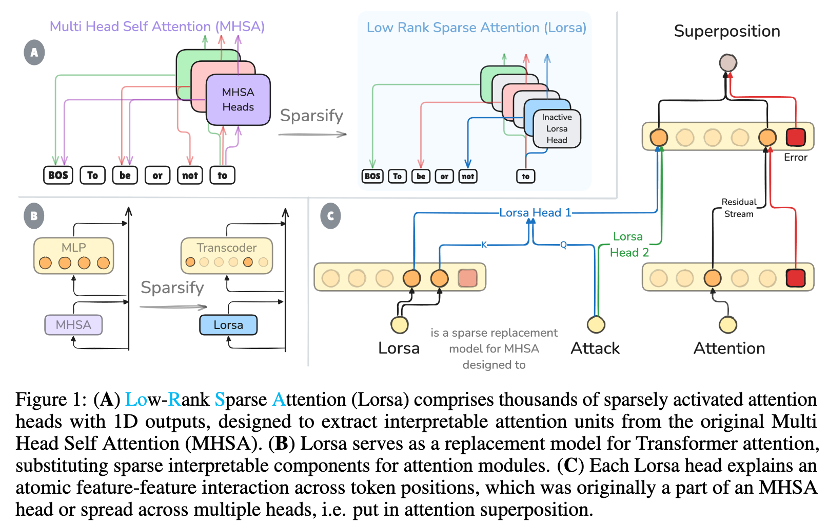
Lorsa(Low-Rank Sparse Attention)的出现,正是为了破解这一难题。它通过构建一个高度稀疏的替代模型,将原本纠缠在一起的注意力计算分解为多个独立的、可理解的“注意力单元”。每一个Lorsa头(Lorsa Head)都只负责一个明确的语义功能——比如识别“第九章第十一节”这样的章节编号、执行加法运算中的某一步,或者在不同语言中完成词语接龙。
与Anthropic主要针对MLP层进行稀疏化不同,Lorsa首次实现了对注意力层的稀疏化分解,填补了Transformer可解释性研究中的关键空白。
04 国际学界认可,从跟跑到领跑
这项研究引起了国际同行的广泛关注。
Anthropic可解释性研究负责人公开表示,该框架解决了“困扰他们很长时间的难题”。在今年6月Anthropic主办的可解释性线上研讨会上,Anthropic联合创始人将邱锡鹏团队列为全球该领域四个最值得加入的研究机构之一。
“在注意力分解这一核心问题上,我们首次实现了对头部机构的领先”,邱锡鹏自豪地表示。
05 百倍效率突破,国产算力支撑大规模解释
可解释研究长期面临工程化挑战。
随着模型规模增大,解释成本呈指数级增长。例如,解释一个90亿参数的模型,需要训练500亿参数的稀疏替代模型。如此大规模的计算,无法依赖现有开源框架。
团队从零开始构建整套训练系统,在国产GPU上实现算子级优化,最终取得数百倍的效率提升,为大规模机理解释提供了工程基础。
项目地址:https://github.com/OpenMOSS/Language-Model-SAEs
06 研究路线总览
2024年初,我们意识到了稀疏自编码器Sparse AutoEncoder (SAE)可以无监督地从模型中抽取数以百万的特征,这些特征其中70%(感性估计,与实现方法与模型尺寸有关)以上都有可理解的意义,可以解释模型70%(同感性估计)以上模型activation中的信息量(用方差衡量)。除了这些数据之外,很重要的性质在于训练SAE全程采用自监督的模式,即广泛的语料分布与自监督稀疏约束的重构训练,这些是这种方法可以规模化的根本。此外,自监督训练使得我们可以最小化地引入对模型的先验,让模型中的解释结构尽可能自发地显现出来。
此外,仅仅理解“某层的activation分布”在总体的研究计划中只是阶段性的,要尝试理解整个模型,需要让参数和activation有机地结合起来。我们有个不严谨的说法:weight就是activation;activation就是weight。activation需要数据来激活权重,但权重又无法脱离数据单独被理解
我们的研究路线如下:
1. 2024年初:围绕着SAE在activation空间中找到的特征如何与模型的参数互动,例如我们可以看到一些特征如何通过attention流动,贡献到其他token处激活的feature,我们称之为回路
代表工作1,在简单的下棋模型中,初步观察到了可解释的回路:Dictionary learning improves patch-free circuit discovery in mechanistic interpretability: A case study on othello-gpt
代表工作2,在小语言模型上扩展了我们的方法,此时我们已经初步探索了稀疏替代模型和注意力层的QK回路分析,这两个核心的思想在2025年大放异彩,但这篇工作没有很深刻地强调和发扬这些想法,当时团队的理解还不是很成熟。Automatically Identifying Local and Global Circuits with Linear Computation Graphs
2. 2024年底:我们意识到GPT2这个尺度的小模型能力受限,没有展现出SAE的可扩展性,因此我们做了Llama-3.1-8B的开源SAE集合,被MIT,Google Deepmind等机构使用,被一篇SAE综述评述为SAE这条线工作的开创性进展Llama Scope: Extracting Millions of Features from Llama-3.1-8B with Sparse Autoencoders
3. 2025年初:在规模化和初步的回路分析都完成后,我们认为接下来的核心任务还是改进我们的回路分析方法,因此稀疏替代模型(即稀疏的SAE可以替代MLP,直观上来说,这使得我们不仅可以稀疏化activation,也稀疏化了weight即计算)比SAE这类仅重构activation的更本质,回路分析的性质也更好。Anthropic也采用这条路线,2025年三月,他们发布了一个改进型的替代模型Cross Layer Transcoder, CLT,在他们的circuit tracing paper;我们的主要工作是研究注意力层的替代模型,我们称之为Lorsa:Towards Understanding the Nature of Attention with Low-Rank Sparse Decomposition
4. 现在:Lorsa和CLT形成了一种互补。我们现在已经具备了可以完全稀疏替代Transformer的技术路线,我们现在正在整理我们的技术报告,争取在Anthropic之前发布。
在这条主线之外,我们也探索了一些应用,例如Transformer和Mamba的相似性Towards Universality: Studying Mechanistic Similarity Across Language Model Architectures
以及偏技术性的训练提升方式:Attention Layers Add Into Low-Dimensional Residual Subspaces
