
一、项目亮点
在分布式系统和高性能计算的世界里,GPU 利用率、系统稳定性、可观测性,一直是困扰研发团队的三大挑战。今天,我们正式开源 VCCL(Venus Collective Communication Library)- 一款由创智、基流、智谱、联通、北航、清华、东南联合研发的 GPU 集合通信库增强方案,以三大核心能力,重新定义 GPU 集群通信体验。
1.在效率上,通过智能调度将通信任务卸载至 CPU,实现SM-Free通信,进一步实现 PP 工作流的深度交叠和全局负载均衡,缩短空闲时间、提升效能;
2.在稳定性上,依托自研容错算法,有效应对网口 Down 和交换机故障,单次迭代内即可就地恢复,系统故障率降低超 50%;
3.在可观测性上,提供细粒度流量可视化,支持研发调优与网络拥塞检测。
二、架构概览
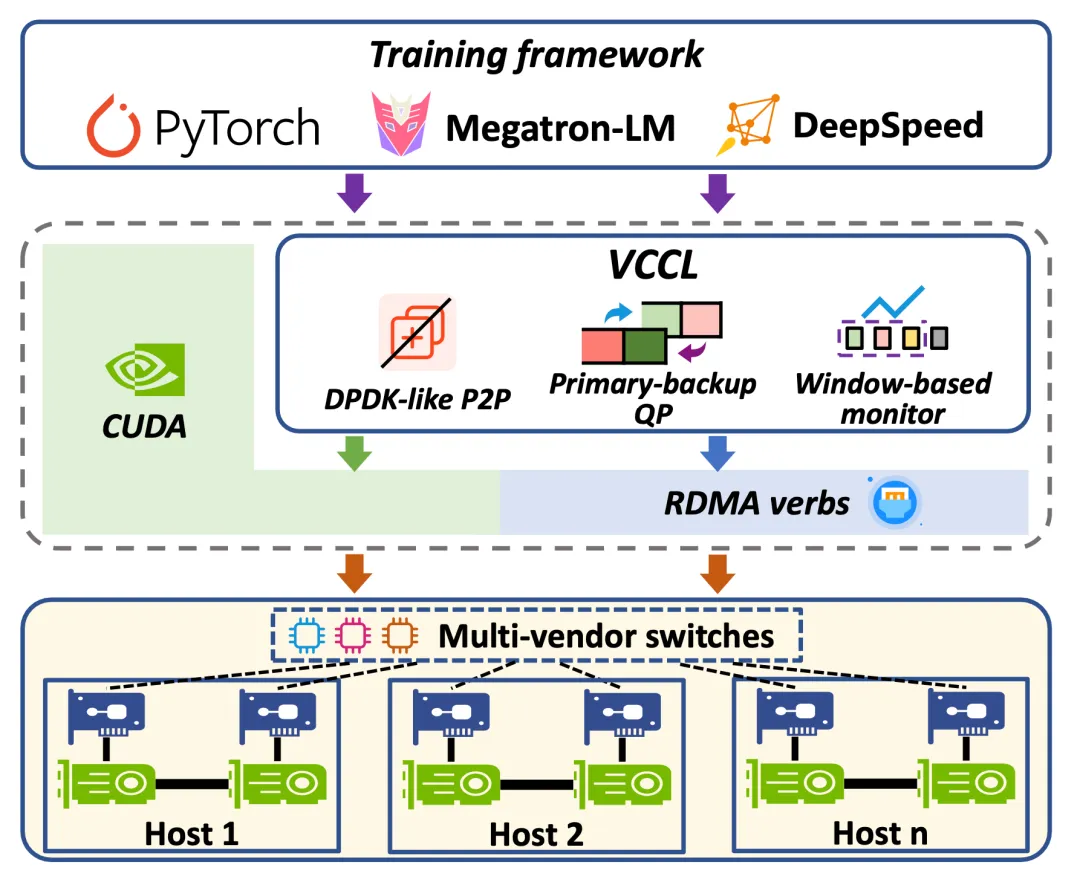
开源代码仓库:https://github.com/sii-research/VCCL
三、更高效:智能调度,让GPU 时刻满载
VCCL 的目标不仅是提升通信效率,更是要让 GPU 算力得到最大化释放,通过 DPDK-like P2P,VCCL 将通信任务合理卸载至 CPU,并在 PP 工作流中实现深度交叠和全局负载均衡,大幅缩短 GPU 空闲时间,在开源框架的SOTA性能之上,端到端算力利用率(TFLPOS)可进一步提升2%-6%。
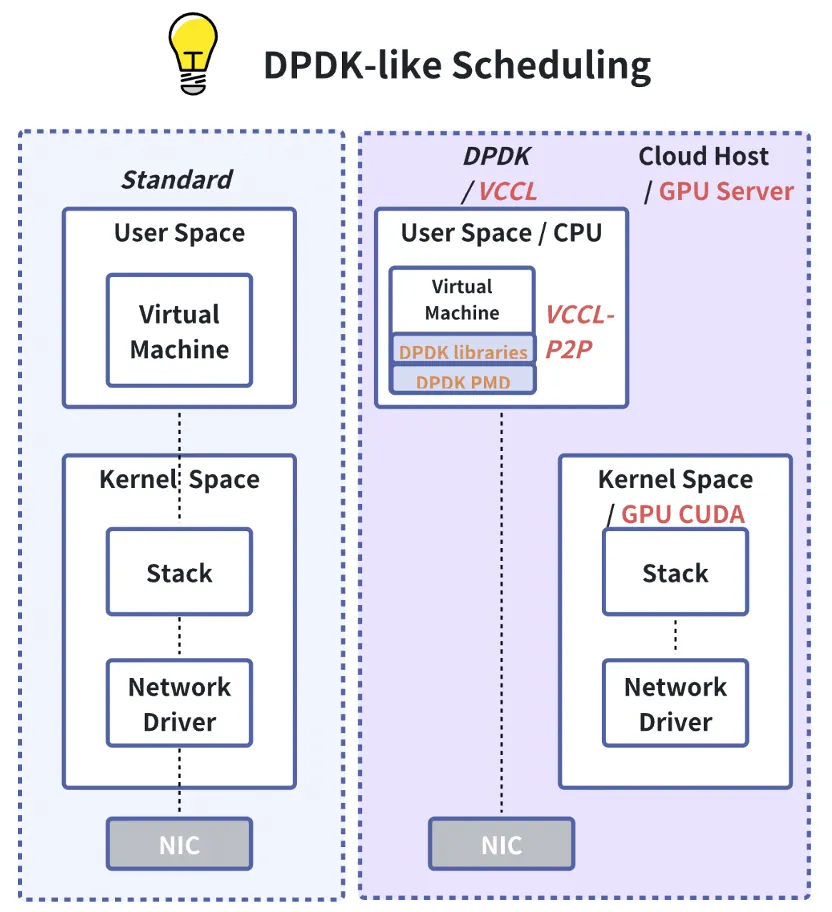
提出的高性能调度技术,可将用于通信的GPU SM资源释放,实现 SM-Free P2P 通信,实测显示P2P 占用的2-4个GPU SM 得以全部释放,并用于计算;
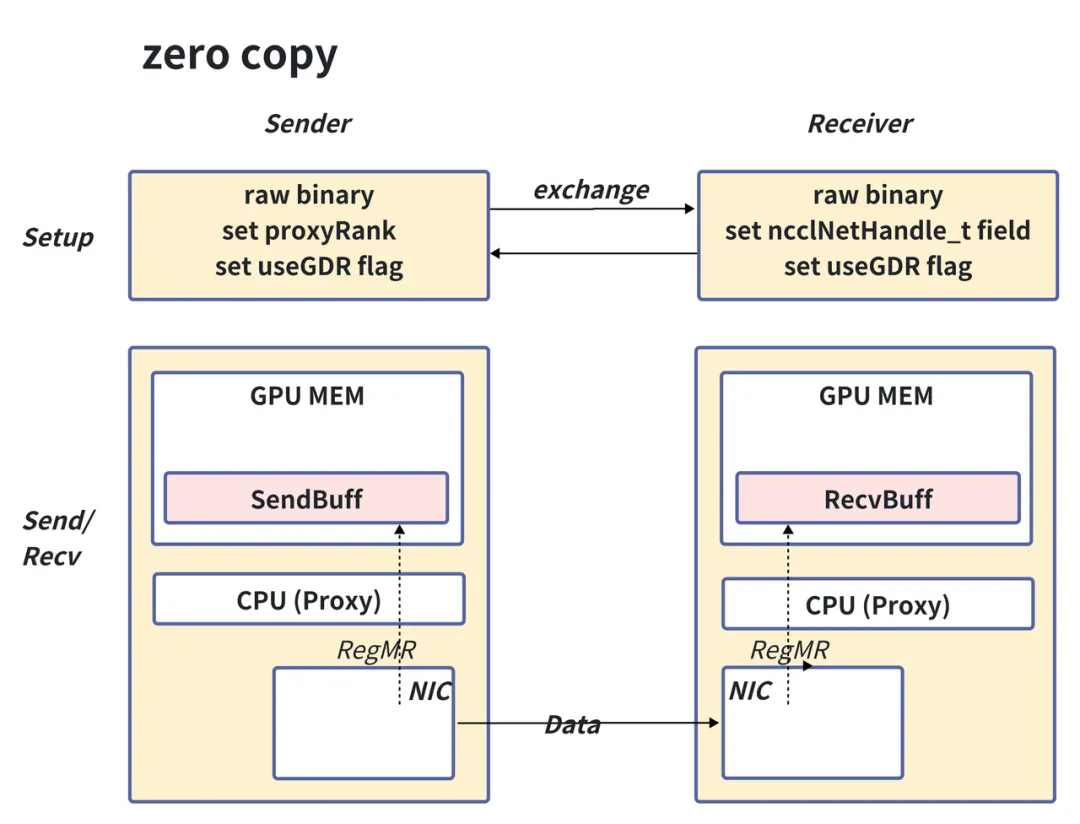
通过使用零拷贝(zero copy)技术替代传统数据传输方式,既减少了数据传输次数,又减去了不必要的GPU与CPU同步开销。VCCL 在小消息(低于32KB)下的通信延时是原生 NCCL 的62.6%;是原生NCCL + zero copy的73.2%。
通过在 PP 工作流中GPU的计算和卸载至CPU的通信进行深度交叠,并进一步解决 PP 负载不均衡的问题,可综合提升整网训练性能。
VCCL 不仅在理论上推演通过,也通过实测数据,验证了 CPU 分担通信 → GPU 空间让渡给计算 → 计算性能提升 → PP工作流深度交叠与负载均衡 →整网训练性能提升的完整闭环。
四、更稳定:自研容错算法保障运行无忧
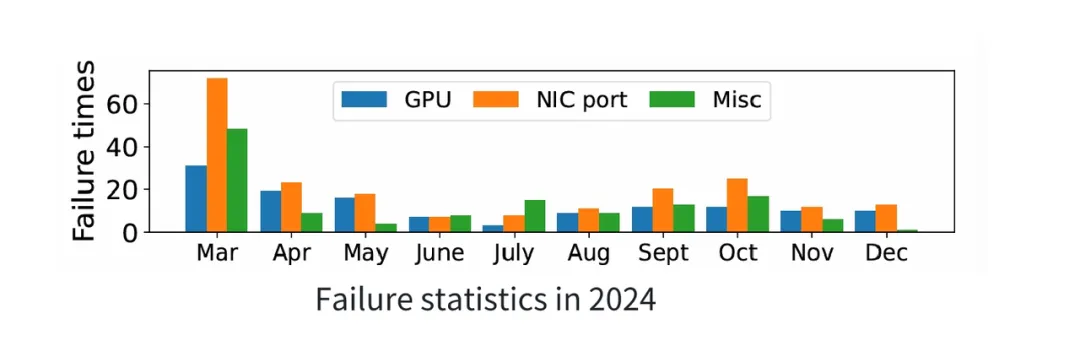
在大规模分布式训练中,网络故障几乎是不可避免的风险源。常见场景包括:网口 Down、交换机侧异常等,其中网口故障比例最高(如下图所示)。一旦发生故障,对应的通信队列对(QP)在超时后无法继续发送,会触发 AEQ 事件 并立刻进入 ERR 状态。最终结果是整体集合通信操作被阻塞,大模型训练失败,待到超时时间结束,任务会被 watchdog 强制退出。
面对链路故障,现有的业界方案往往难以满足训练过程中的即时恢复需求:
NCCL:依赖 timeout 参数,往往意味着训练中断与长时间等待。
流量工程或 checkpoint 快速恢复:虽然可以缩短故障恢复时间,但依然需要重启或回滚,无法保证训练的连续性。
主流网口聚合方案:适合应对突发的链路抖动,但无法支持单端口集群场景。
VCCL 设计了一套轻量级的原地恢复容错机制,在不增加系统负担的前提下,大幅提升整体稳定性。
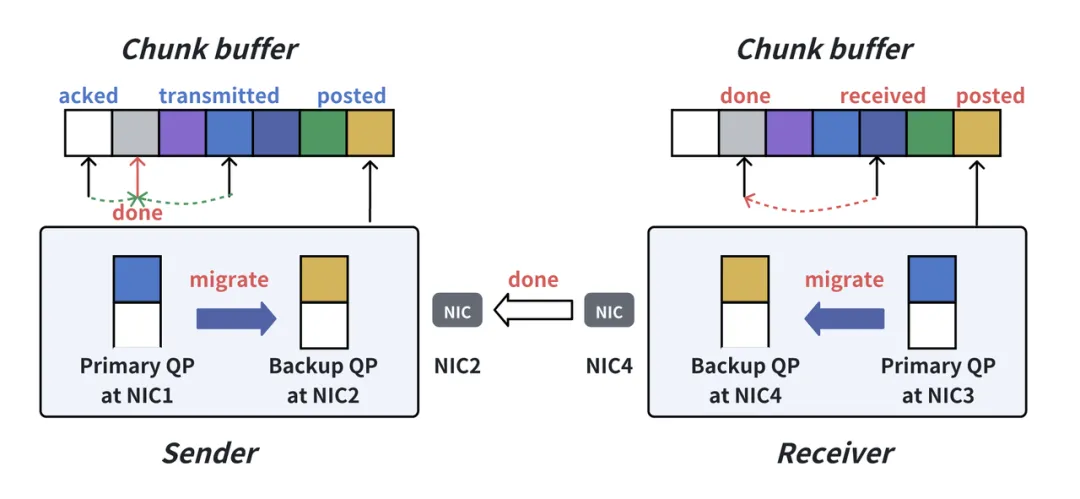
1. 轻量级原地恢复
当交换机或网卡出现故障时,VCCL 能在底层实时检测并接管,自动将流量无差别导向备份网口完成通信。整个过程对上层完全透明,无需应用层感知,也无需额外干预。
2. 系统鲁棒性更强
当原链路恢复后,VCCL 会立即检测并将流量切换回主 QP,集合通信性能完全恢复。同时,系统能够持续应对新的链路故障,保障长时间训练的稳健运行。
3. 高兼容性,零额外开销
在训练正常运行时,引入容错机制的 VCCL 与原生版本在性能表现上一致。
对于短暂的端口抖动,VCCL 不会直接介入,充分利用硬件自带的重传机制保证训练进行。
容错机制还能与传统方案(如 checkpoint 恢复)兼容,GPU 故障等场景同样能稳妥处理。
直接成效
通过这一机制,VCCL 能够将集群故障率降低超过 50%,真正做到“网络出故障了也能原地拉回”,让大模型训练不再轻易被打断。
五、更可观测:细粒度流量可视化
在分布式训练中,传统基于计数的统计方式存在明显不足:粒度粗、准确度差,很难精确定位训练过程中的慢节点或慢链路。
为此,我们在 VCCL 中设计并实现了 Flow Telemetry ——一种微妙级的 GPU 间点对点流量观测机制,为研发团队提供更细粒度的网络可观测能力。
三大优势
1. 微秒级点对点测量
支持 GPU 间微秒级别流量探测,能够清晰捕捉训练过程中通信速率的细微变化。
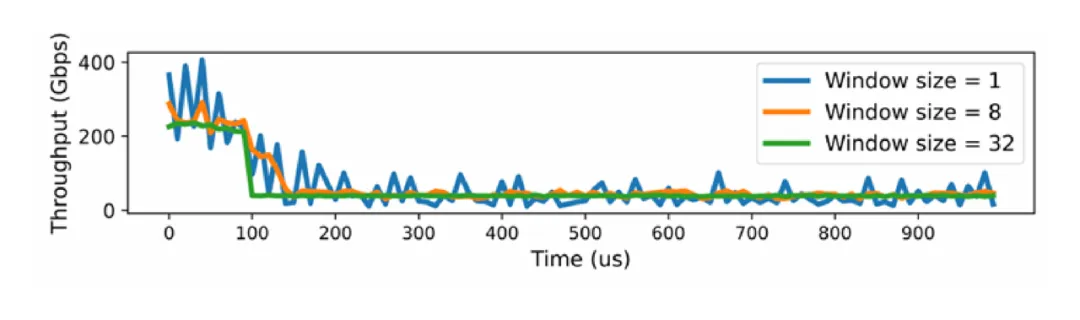
2. 实时拥塞检测
Flow Telemetry 能够实时统计端口上未完成的 WR(work request)数量,并据此推测工作队列长度变化,从而精准判断网络是否出现拥塞。
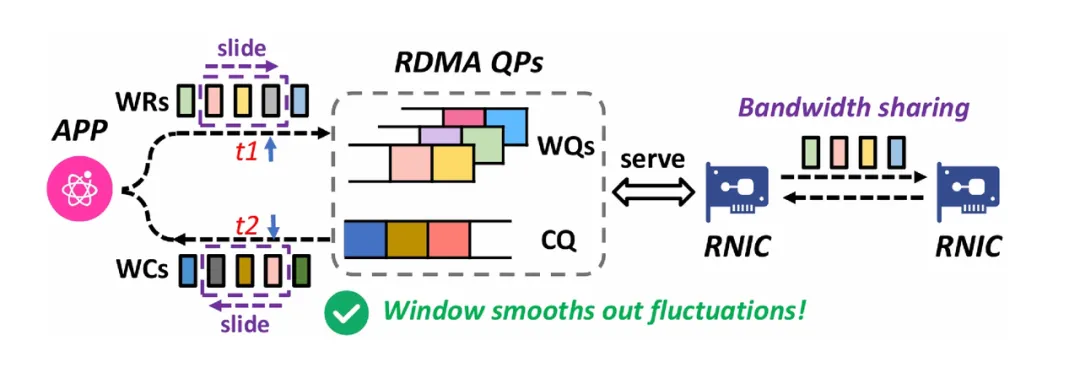
3. 滑动窗口带宽测量
通过引入滑动窗口机制,Flow Telemetry 可以在动态环境下实现更准确的流量带宽测量,让研发团队在优化通信和排查瓶颈时有据可依。
价值
Flow Telemetry 让训练过程从“黑盒”变成“透明玻璃盒”,研发人员能够 快速定位慢节点、发现拥塞点、优化通信模式,为进一步提升 GPU 利用率打下基础。
六、异构服务器机型支持
当前GPU服务器面临多厂商异构的问题,我们遇到了因PCIe拓扑结构差异导致的网络不通或性能降低。具体表现为跨设备连接不通及多网卡端口间流量不均衡,致使RDMA性能未达预期。为系统性地解决此问题,我们针对不同硬件配置设计了相应的优化方案。
PCIe的异构情况
一个GPU,一个RNIC, 一个端口
一个GPU,一个RNIC, 两个端口
方案:RDMA QP平均使用两个端口
两个GPU,两个RNIC, 两个端口
两个GPU,两个RNIC, 四个端口
方案:一个GPU使用一个RNIC
方案:RDMA QP平均使用所有的端口
七、为什么选择 VCCL?
面向开发者:从易用性出发,开源、透明、可扩展。
面向研发:为分布式任务和高性能计算提供稳定可靠的通信调度保障。
面向未来:高效、稳定、可观测,是下一代系统的必备特性。
VCCL 已经在 GitHub 上开源,欢迎大家来体验、反馈、共建!
链接:https://github.com/sii-research/VCCL
上海创智学院携手来自31所顶尖高校的博士生及产业力量,以“建中研、干中学”人才培养模式,培养具备国际竞争力的实战型AI基础设施人才!开源周只是起点,开源生态现已启航,让我们以开放协作,加速技术跃迁,诚邀更多师生和全球开发者加入我们,共铸开放、创新的普惠AI基座!
