
当前,全球AI竞争日趋激烈。在最高难度AI评测中霸榜,全球TOP10模型中8个未开源,核心基础设施遭遇封锁。AGI的火种正被少数力量垄断。我们的回应是:以开源生态打破壁垒,以实干人才推动普惠。
因此,我们正式启动“创智AI基础设施开源周”活动,发布五大核心项目,涵盖下一代训练框架、推理引擎、万卡集群通信库与智能运维系统。
一、项目亮点
Metis框架攻克FP4低比特训练难题,实现大模型训练的低精度量化突破。该框架聚焦以下核心优势:
1. 精度保持:实现稳定收敛,精度接近无损
2. 计算效率优异:通过优化核心算子设计,有效降低训练过程中的计算开销
3. 生态适配:支持新一代芯片的MXFP4/NVFP4格式,深度集成Megatron分布式框架
二、架构设计
Metis:全分布式低比特训练框架的核心策略
1. 谱分解拆解宽分布
2. 自适应谱学习照顾长尾
3. 双范围正则化压缩数值分布
技术论文: https://arxiv.org/pdf/2509.00404
开源代码仓库:https://github.com/sii-research/Metis
2.1 大模型的算力天花板
随着大模型规模一路攀升,参数量早已突破千亿,训练数据突破万亿。如此庞大的规模意味着训练成本高到惊人。以 xAI 训练 Grok4 为例,需要 20 万张 GPU 同时在线,背后是天文数字的硬件投入和持续的能耗开销。算力消耗已经成为限制大模型发展的最大瓶颈。于是,业界普遍在寻找一条出路:如何在保持模型性能的同时,大幅降低训练开销?
2.2 为什么是低精度量化?
核心思路就是压缩。把参数、激活和梯度这些张量从 FP32 压到低比特(FP8、FP4),计算和存储开销都会大幅下降。FP8 已经逐渐成为工业界的标准,而 FP4 被认为是下一代的关键突破口。更重要的是,新一代算力芯片已经适配 MXFP4 与 NVFP4的数据格式,原生支持 FP4 运算,硬件条件已具备。但问题在于:FP4 很难稳定收敛。
2.3 FP4 的困境:FP4表示范围与模型数值分布的矛盾
一言以蔽之,FP4 的最大问题就是“分布太宽,表示太窄”。FP4 的数值表示范围极为有限,而大模型的训练数据分布跨度又极大。两个世界一碰撞,就会出现严重的信息损失和收敛困难。那么,这个问题是否有解呢?针对这一问题,我们进行了长达一年的探索。
参数各向异性:通过对 Qwen、DeepSeek 等大模型的分析,我们发现:参数矩阵往往被少数几个奇异值主导,能量都集中在少数方向。这种现象在训练过程被进一步放大:随着迭代推进,参数、激活和梯度都会迅速表现出各向异性,主导奇异值持续增长,能量分布越来越失衡。
 图1:工业级模型参数的分布奇异化
图1:工业级模型参数的分布奇异化
信息分布的不均衡:各向异性推动主导奇异值快速增长,显著增大参数矩阵方差,导致数值分布范围急剧扩展。且当能量集中在大奇异值方向时,小奇异值对应的信息被不断挤压,甚至接近“隐形”。这些小值虽然幅度不大,却往往蕴含模型细节和长尾知识。一旦在量化过程中被舍弃,就会对模型表现造成实质性损伤。
 图2:参数,激活,梯度矩阵各向异性引发宽数值分布
图2:参数,激活,梯度矩阵各向异性引发宽数值分布
块级量化的偏见:现有的 FP4 格式(如 MXFP4、NVFP4)采用“块级量化”的方式,即同一块数据共享一个缩放因子。但缩放因子由块内的最大值主导,结果是:大数被照顾了,而小奇异值承载的信息被挤压。这在奇异空间表现为谱尾部信号严重丢失,小奇异值的幅度被放大或扭曲,其对应的奇异向量方向发生偏转,直接破坏了训练的稳定性。
 图3:块级量化策略的系统性偏差,对奇异值奇异向量的影响
图3:块级量化策略的系统性偏差,对奇异值奇异向量的影响
2.4 Metis的解法:把问题搬到谱空间
Metis 框架的核心思想是:与其在数值空间里硬抗,不如把问题转换到谱空间(singular spectrum)。这样可以最大限度地缓解宽分布带来的冲突。
1. 谱分解拆解宽分布: 我们的研究发现,虽然奇异值分布极度不均衡,但奇异向量的数值分布近似高斯分布,尺度相对稳定。Metis 因此引入谱分解,将权重矩阵分解为主导成分和长尾成分:主导奇异值部分独立量化,避免过度放大;长尾残差部分统一量化,分布均匀、误差更可控。随机化降维:谱分解计算复杂度巨大,Metis引入随机化降维技术,谱分解过程可以在低维空间高效完成,计算开销远低于全矩阵分解。
2. 自适应谱学习照顾长尾: 大奇异值的学习天然就很强,反而是小奇异值容易被忽视。Metis 在谱空间引入“自适应谱学习”机制,对中低奇异值方向的梯度进行逆归一化缩放,增强更新强度。这样既能保证长尾特征不被淹没,又避免了噪声放大的风险。
3. 双范围正则化压缩数值分布: Metis 还提出“双范围正则化”机制,既约束过大值,又抑制近零值,从而压缩整体参数分布范围。这样做的好处是:降低矩阵方差;减少量化误差;以及提升低比特训练的稳定性。
实验结果:FP4 也能稳定收敛
在不同规模模型的实验中,Metis 的 FP4 训练损失曲线几乎与 FP32 基线保持一致。而使用原生 FP4(如 MXFP4)的训练则出现严重震荡,甚至无法收敛。
 图4:1.1B模型 FP4训练对比
图4:1.1B模型 FP4训练对比
在下游任务中,Metis 的表现同样亮眼:相比直接量化方法,准确率显著提升,整体性能接近 FP32,误差控制在 1% 以内。
表一:1.1B模型FP4下游任务性能比较
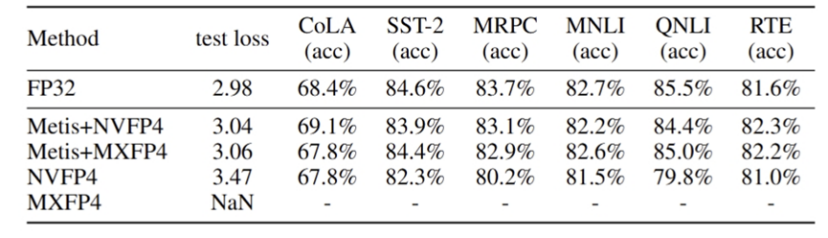
换句话说,Metis 让 FP4 从“不可能完成的任务”,变成了可以落地的工业级方案。
2.5 战略意义:国产化与全栈优化
我们研究Metis的初衷是通过大模型训练算法层面的创新推动国产 AI芯片与系统的发展:
芯片设计:Metis 为国产芯片指明并验证了低比特训练的路径,未来芯片可以针对低比特高吞吐计算优化架构,在降低功耗和成本的同时提升国际竞争力。
训练框架:Metis 推动国产训练框架深度适配低精度算子和新数据格式,让低精度量化成为框架的“原生能力”。
2.6 开源与合作:共建大模型低精度训练生态
Metis 将深度适配分布式训练框架 Megatron,并在大规模任务中显著提升效率与稳定性。Metis 项目已 100% 开源,包含完整算法、模型、训练脚本和文档。
我们期待更多学术界和产业界的同仁加入,共同推动低精度训练的发展。
上海创智学院携手来自31所顶尖高校的博士生及产业力量,以“建中研、干中学”人才培养模式,培养具备国际竞争力的实战型AI基础设施人才!开源周只是起点,开源生态现已启航,让我们以开放协作,加速技术跃迁,诚邀更多师生和全球开发者加入我们,共铸开放、创新的普惠AI基座!
